问问AI
概念
问问节点作为画布中最核心的节点,问问AI 通过使用大模型来串联其他资源通过提示词完成用户需求:
- 添加上下文:通过添加上下文来将上一个节点生成的内容作为问问AI节点的待处理资源
- 选择知识库:在问问中同样可以添加知识库,实现大模型对知识库内容的检索,结合提示词生成新内容
- 选择模型:根据业务需求选择不同模型,包括:
- 多模态模型(可处理图片)
- Think模型(支持思维链思考)
- 普通大模型
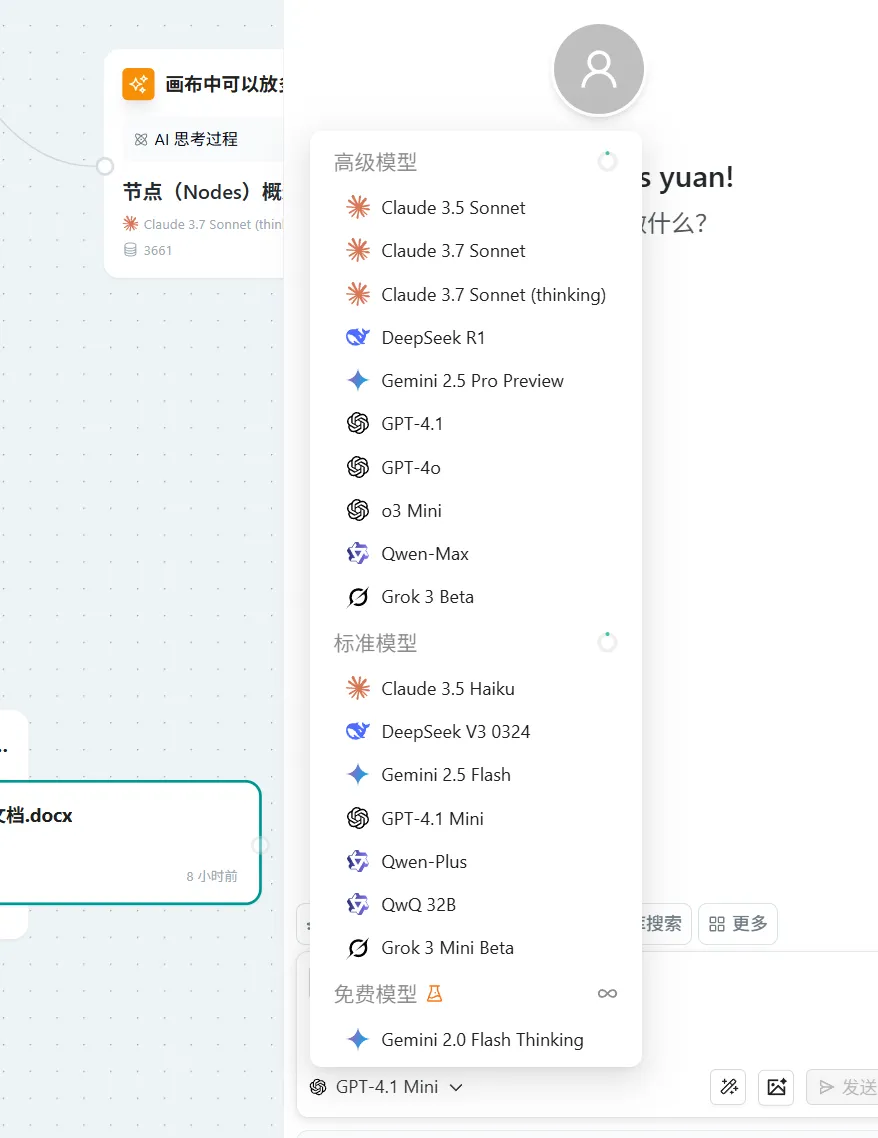
模型选择
根据业务需要选择合适的模型,需要添加图片的请注意选择对应的视觉支持模型
模型介绍
| 模型类别 | 模型特性 | 模型名称 | 模型描述 (基于公开信息补充) | 模型擅长 (基于公开信息补充) |
|---|---|---|---|---|
| 高级模型 | 多模态 | Claude 3.5 Sonnet | Anthropic 推出的模型,作为 Claude 3 Sonnet 的升级版,在多个基准测试中表现优于 GPT-4o 和 Gemini 1.5 Pro。擅长编码、写作和视觉数据提取(包括从不完美图像中提取文本),并引入了创新的 Artifacts 功能。是首个公开测试计算机使用功能的前沿模型。 | 编码、写作、视觉数据提取(尤其擅长处理不完美图像)、代理任务、工具使用、计算机使用(测试版)。在软件工程和图像信息提取方面能力突出。 |
| 高级模型 | 多模态, 混合推理 (Hybrid Reasoning) | Claude 3.7 Sonnet | Anthropic 当时发布的最智能模型,是市场上首款混合推理模型。引入了“扩展思考”能力,能以可见的、细致的步骤解决复杂问题,并可快速响应。在编码和驱动 AI 代理方面表现优异。 | 复杂问题求解(通过扩展思考)、高级编码、驱动 AI 代理、快速响应生成、长文本输出(高达 128K token,部分测试版)、支持 200K 上下文窗口。 |
| 高级模型 | 多模态, 混合推理 (可选扩展思考模式) | Claude 3.7 Sonnet (扩展思考模式) | Claude 3.7 Sonnet 的一个可选工作模式。启用后,模型会投入更多时间进行问题分解、方案规划和多角度探索,通过可见的、逐步的推理过程来解决复杂问题,尤其在数学和科学领域表现更佳。无需显式提供思维链提示。 | 复杂问题求解、需要详细推理过程的任务(尤其是数学、科学)、需要解释思考步骤的场景、深度分析与规划。 |
| 高级模型 | Think 模型 (推理中心) | DeepSeek R1 | 由 DeepSeek 推出的以推理为中心的模型(早期版本为 R1-Lite-Preview),采用强化学习优先的训练方法。旨在与 OpenAI o1 等模型竞争,在逻辑推理、数学和编码方面表现突出,具备事实核查和复杂问题规划能力。 | 逻辑推理、代码生成与补全、数学问题求解 (在 AIME, MATH-500 等基准测试中表现优异)、复杂问题规划与解决、事实核查。 |
| 高级模型 | 多模态, 强推理 (可进行响应前思考) | Gemini 2.5 Pro Preview | Google 当时发布的最智能、推理能力最强的模型预览版。能够在响应前进行思考推理,提升性能和准确性。在 LMArena 人类偏好排行榜上名列前茅,具备强大的编码、数学和科学能力,并支持多模态处理和超长上下文。 | 复杂推理(包括响应前思考)、高级代码生成与理解、数学与科学问题求解、多模态信息处理、长上下文任务、深度研究 (Deep Research)。 |
| 高级模型 | 多模态, 编码优化, 超长上下文 | GPT-4.1 | OpenAI 推出的专注于编码能力提升的模型系列 (包括 standard, mini, nano)。相比 GPT-4o,在编码、指令遵循和长上下文处理方面有重大改进,支持高达 100 万 token 的上下文窗口。在格式遵循、减少幻觉和记忆方面更稳健,主要通过 API 提供。 | 高级代码生成与理解、严格的指令遵循、超长文本处理 (1M token 上下文)、企业级应用、需要高格式遵循度和低幻觉率的任务。 |
| 高级模型 | 多模态 (文本, 语音/音频, 图像, 视频能力), 快速响应 | GPT-4o ("omni") | OpenAI 的旗舰模型 ("o" 代表 "omni"),原生集成了文本、语音/音频和视觉处理能力。提供 GPT-4 级别的智能,但速度更快,尤其在实时语音交互和图像理解方面有显著提升。 | 实时多模态交互(语音对话、图像讨论)、文本生成与理解、代码生成、数学与逻辑推理、快速响应任务。 |
| 高级模型 | 多模态, 推理增强, 图像理解 | o3 Mini (OpenAI) | OpenAI 推出的新型推理模型,能够“用图像思考”,即分析图像并用于推理。专门设计用于处理需要逐步逻辑推理的问题,擅长科学、数学和编码任务。 | 图像理解与推理、复杂问题求解、科学/数学/编码任务、逐步逻辑推理。 |
| 高级模型 | 大规模 MoE 模型, 多模态 (Qwen-VL), 20T tokens 训练 | Qwen2.5-Max (通义千问2.5-Max) | 阿里巴巴云通义千问大语言模型系列的最新版本。在多个基准测试中超越 DeepSeek V3 和 Llama-3.1-405B。使用 20 万亿 tokens 训练,拥有广阔的知识库和强大的通用 AI 能力。Qwen-VL 是该系列的多模态版本,支持图像、文本和 bounding box 输入输出。 | 中文自然语言处理、长文本摘要与生成、文档问答、代码生成、图像理解、数学 (提升 75%)、代码能力 (提升 102%)、指令遵循 (提升 105%)。 |
| 高级模型 | 实时信息获取, 1M token 上下文, 强化学习, 图像分析 | Grok 3 Beta | xAI 推出的旗舰模型,能够分析图像并回答问题。在多个 AI 基准测试中优于 GPT-4o,拥有 100 万 token 的上下文窗口,并通过大规模强化学习改进了高级推理能力。具备 DeepSearch (实时互联网分析) 和 Big Brain Mode (复杂任务) 等功能。 | 实时信息获取、复杂问题推理、数学问题求解 (AIME)、知识密集型问题 (GPQA)、图像分析、个性化对话。 |
| 标准模型 | 速度最快, 低延迟, 高效, 200K 上下文 | Claude 3.5 Haiku | Anthropic 推出的速度最快的模型,以极低的延迟提供高级编码、工具使用和推理能力。适用于面向用户的产品、专门的子代理任务,以及从海量数据中生成个性化体验。 | 快速响应的客户服务、内容审核、简单问答、实时翻译、轻量级视觉任务、编码推荐、数据提取和标注、内容审核、处理大型数据集、分析财务文档、从长上下文信息中生成输出。 |
| 标准模型 | 671B MoE, 128K 上下文, 推理增强, 代码优化 | DeepSeek v3 0324 | DeepSeek V3 的更新版本,显著提升了推理性能、编码能力和工具使用能力。支持函数调用、JSON 输出和 FIM 完成等功能。 | 代码生成与补全、数学问题求解、技术文档写作、长篇对话、文档分析、基于检索的 AI 应用、逻辑推理。 |
| 标准模型 | 轻量级, 高效, 多模态, 1M token 上下文, 原生工具使用 | Gemini Flash 2.0 | Google 推出的轻量级、高效率模型,针对速度和成本进行了优化,支持多模态输入和原生工具使用。具有 100 万 token 的上下文窗口。 | 高吞吐量任务、需要快速响应的应用 (如聊天机器人、摘要生成)、成本敏感型应用、多模态推理、大规模信息处理。 |
| 标准模型 | 编码优化, 1M token 上下文, 低成本, 低延迟 | GPT-4.1 Mini | OpenAI 推出的 GPT-4.1 模型家族中的一员,专注于编码能力,旨在以更低的成本和延迟提供接近 GPT-4 级别的能力。具有高达 100 万 token 的上下文处理能力。 | 平衡性能与成本的任务、通用文本生成、数据分析辅助、需要较好理解能力但对速度有要求的场景、长文本处理 (1M token 上下文)、编码任务。 |
| 标准模型 | 多模态, 性能与成本平衡 | Qwen-Plus (通义千问-Plus) | 阿里巴巴达摩院的模型,性能介于 Qwen-Max 和 Qwen-Turbo 之间,提供较好的性能和成本平衡。 | 通用中文任务、文档处理、代码编写、简单图像描述、自然语言处理、计算机视觉、音频理解。 |
| 标准模型 | 32B 参数, 强化学习微调, 推理增强 | QWQ-32B (通义千问) | 阿里巴巴 Qwen 团队推出的实验性研究模型,基于 Qwen2.5-32B 构建,通过强化学习微调以增强推理能力。 | 数学推理 (AIME 24)、编码能力 (LiveCodeBench)、复杂问题求解、思维链生成。 |
| 免费模型 | 轻量级, 推理增强, 实时信息访问 | Grok 3 Mini Beta | xAI 推出的 Grok 3 的轻量级版本,保留了 Grok 的部分特性,如实时信息访问,但规模更小,响应更快。 | 快速获取信息摘要、进行非正式对话、适用于对实时性有一定要求但计算资源有限的场景、数学问题求解、图像分析。 |
| 免费模型 | 多模态 | Gemini 2.0 Flash Thinking | Gemini 2.0 Flash 的一个变体,强调了推理能力,能够在响应前进行思考推理,从而提高性能和准确性。 | 需要快速响应且涉及一定推理步骤的任务、教育场景 (展示思考过程)、轻量级多模态分析、复杂推理、长文本处理。 |
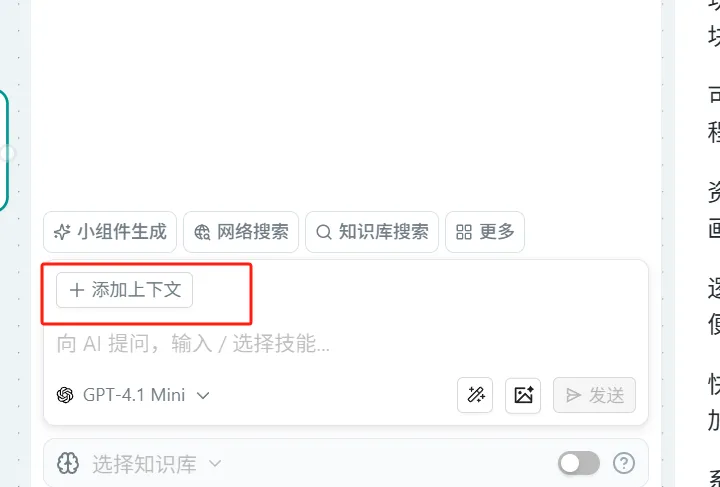
添加上下文
**操作:**通过鼠标点击添加上下文来将其他节点添加到问问AI节点中让大模型作为让大模型来处理的内容

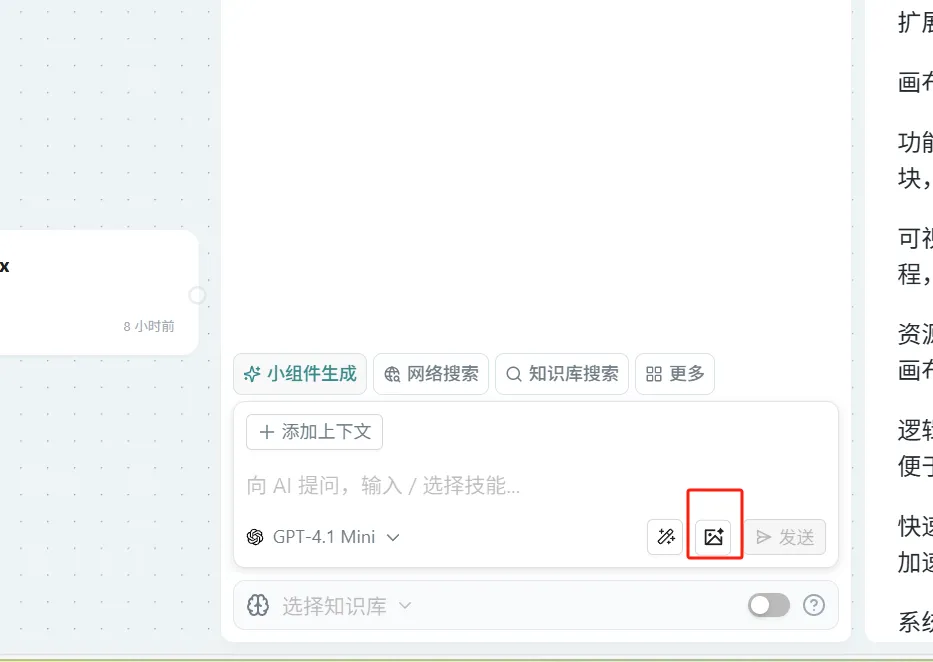
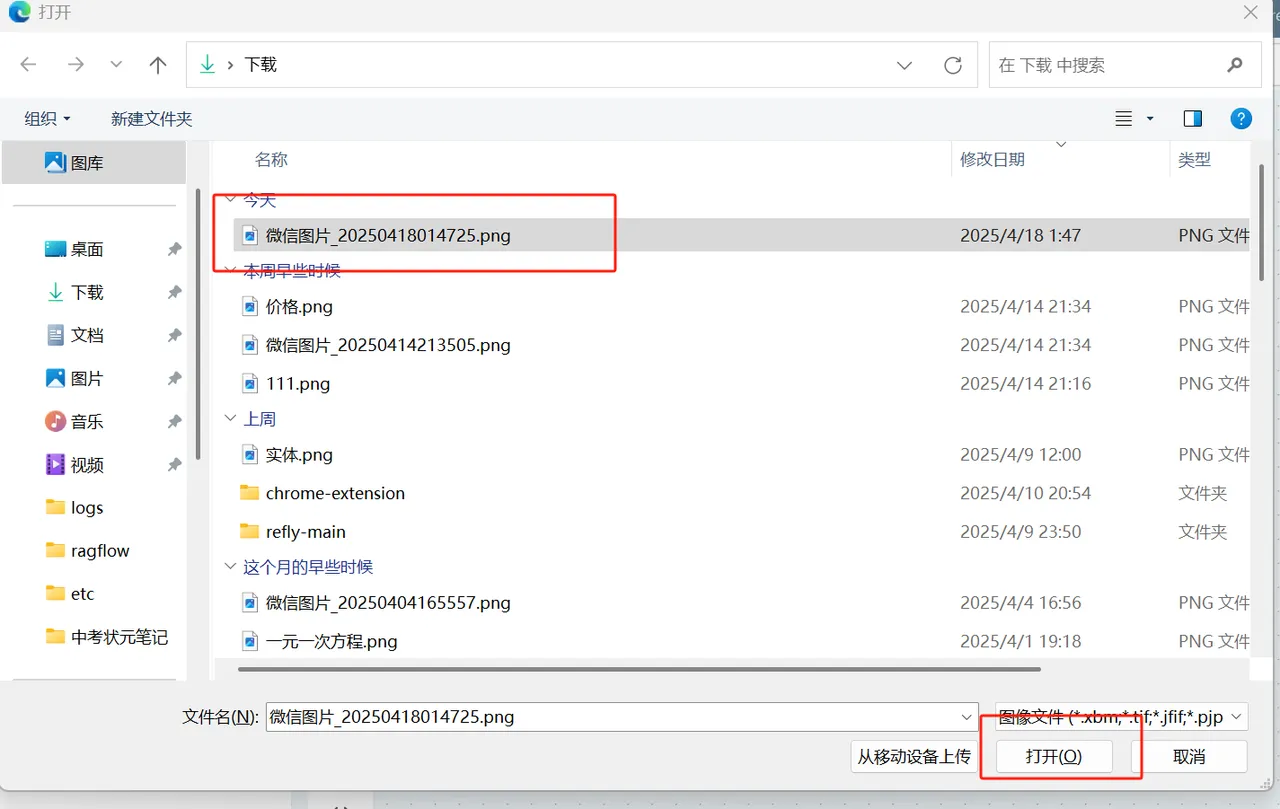
添加图片
**操作:**方法1,点击问问AI 组件上的图片添加图标按钮触发图片添加动作.方法2,也可以直接剪切图片使用CTRL+V 在问问对话框或者直接粘贴通过连线方式让图片成为问问AI的上下文.方法3 直接拖拽图片到画布
技能
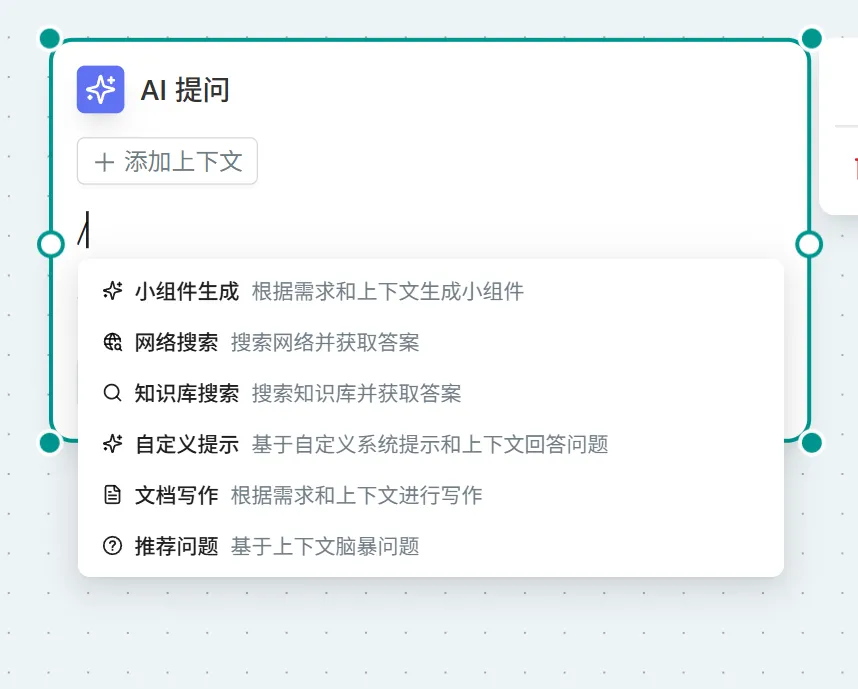
小组件生成
概念:小组件为系统对一些功能的分装,当你选择某个小组件后会调用系统对这部分的封装功能,例如当你调用 Mind Map 小组件时,会做2件事 1.将你的问问AI输出格式化成 Mind Map要求的格式 2.会创建出来一个 Mind Map 的代码块. 注意:你在不选择任何组件时候默认会使用markdown进行输出 组件介绍:
| 名称 | 描述 | 适用场景 |
|---|---|---|
| React | 用于创建可复用的React组件,支持Hooks和UI库集成,使用Tailwind CSS进行样式设计 | 需要构建交互式UI组件时;展示带有状态管理的复杂组件;集成shadcn/ui等组件库时 |
| SVG | 创建矢量图形,自动渲染为可视化图像 | 需要展示logo、图标等矢量图形时;替代位图图像请求时;创建可缩放图形元素时 |
| Mermaid | 生成流程图、时序图等可视化图表 | 需要展示系统架构、业务流程时;制作技术文档中的示意图时;可视化复杂流程关系时 |
| Markdown | 支持富文本格式的文档内容 | 创建技术文档、说明文件时;需要结构化展示文本内容时;制作带格式的说明性材料时 |
| Code | 展示各类编程语言代码片段,支持语法高亮 | 分享可复用的代码示例时;需要保留代码原格式时;展示算法实现或工具脚本时 |
| HTML | 渲染完整网页(单文件包含HTML/CSS/JS) | 展示完整网页原型时;需要交互式演示UI设计时;创建自包含的网页案例时(禁用外部资源引用) |
| Mind Map | 创建层级化思维导图,支持富文本节点和交互式操作 | 知识体系梳理时;项目规划脑暴时;复杂概念可视化时;教学材料的结构化展示时 |
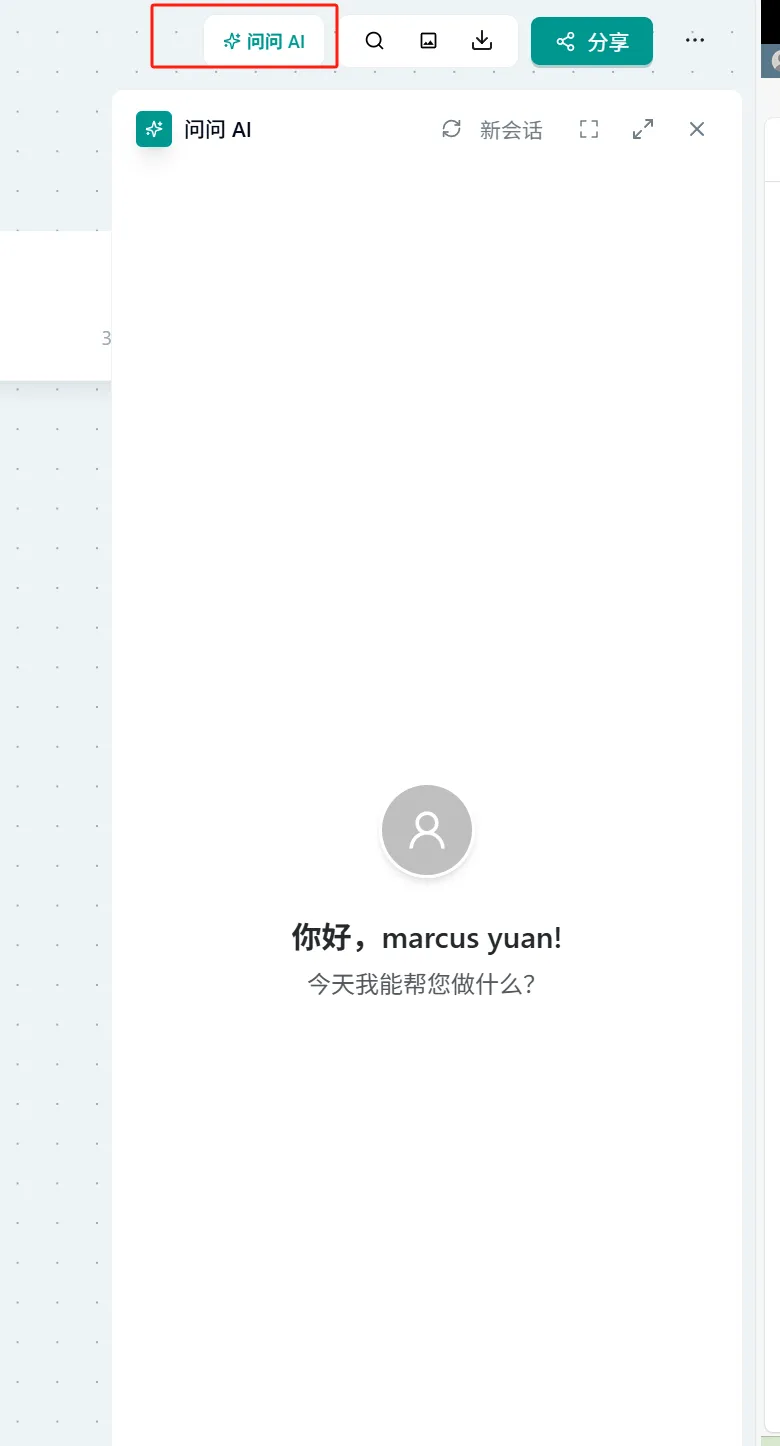
操作:
- 点击页面右上角的 "问问AI" → 选择"小组件生成" → 选择对应小组件
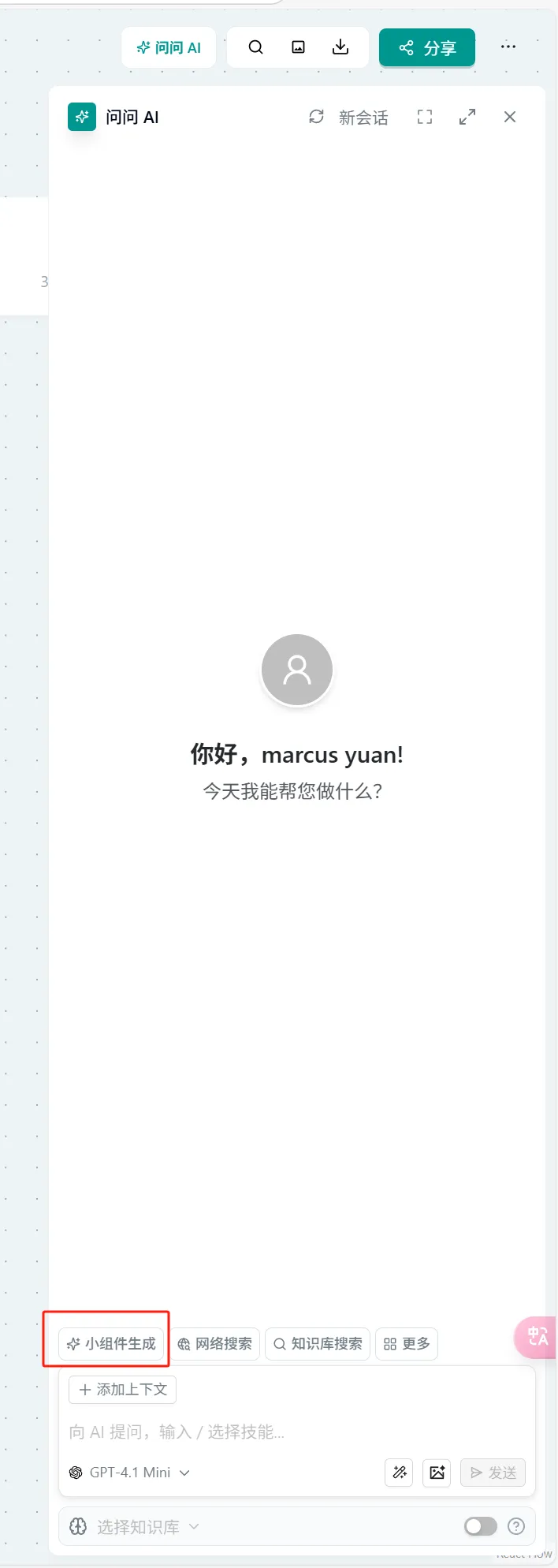

- 在任意问问AI的提问框输入 "/"触发组件列表 → 选择"小组件生成" → 后续步骤与方式1相同
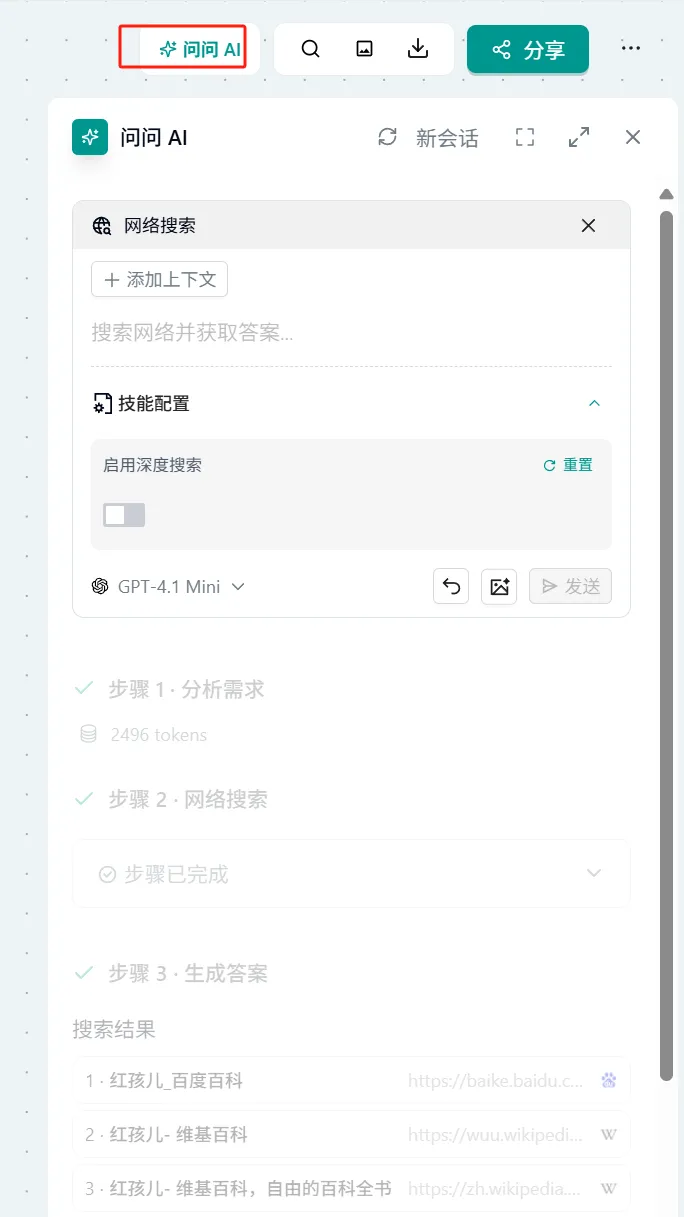
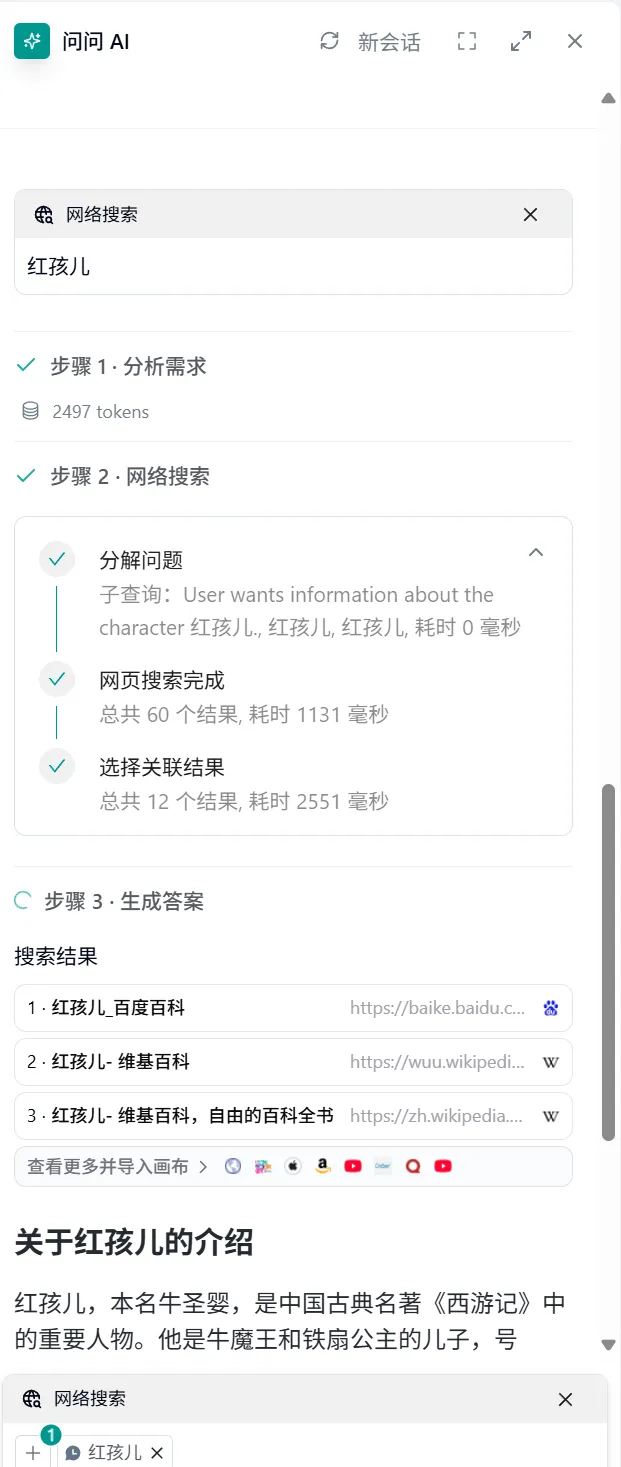
网络搜索
概念:
- 分为两个步骤:
- 在网络上搜索用户提出的问题
- 根据搜索结果调用大模型进行处理并输出结果
- 深度搜索:采用 Deep Search 技术进行深度多轮检索获取内容
操作:
- 点击页面右上角的 "问问AI" → 选择"网络搜索" → 直接输入搜索内容
- 注意:可开启深度搜索开关进行深度搜索
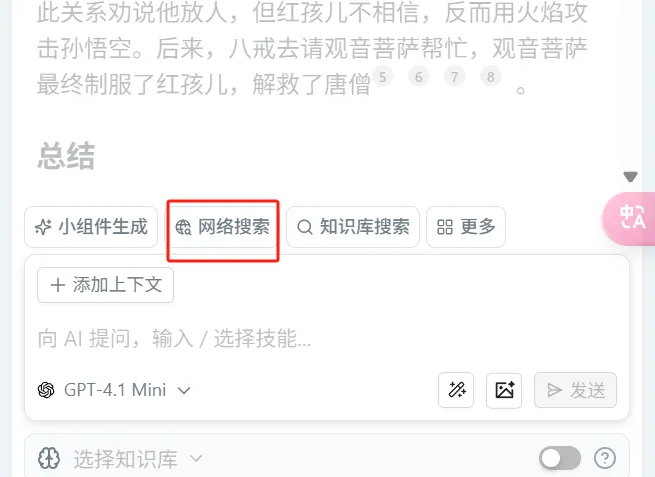



- 在任意问问AI的提问框输入 "/"触发组件列表 → 选择"网络搜索" → 后续步骤与方式1相同
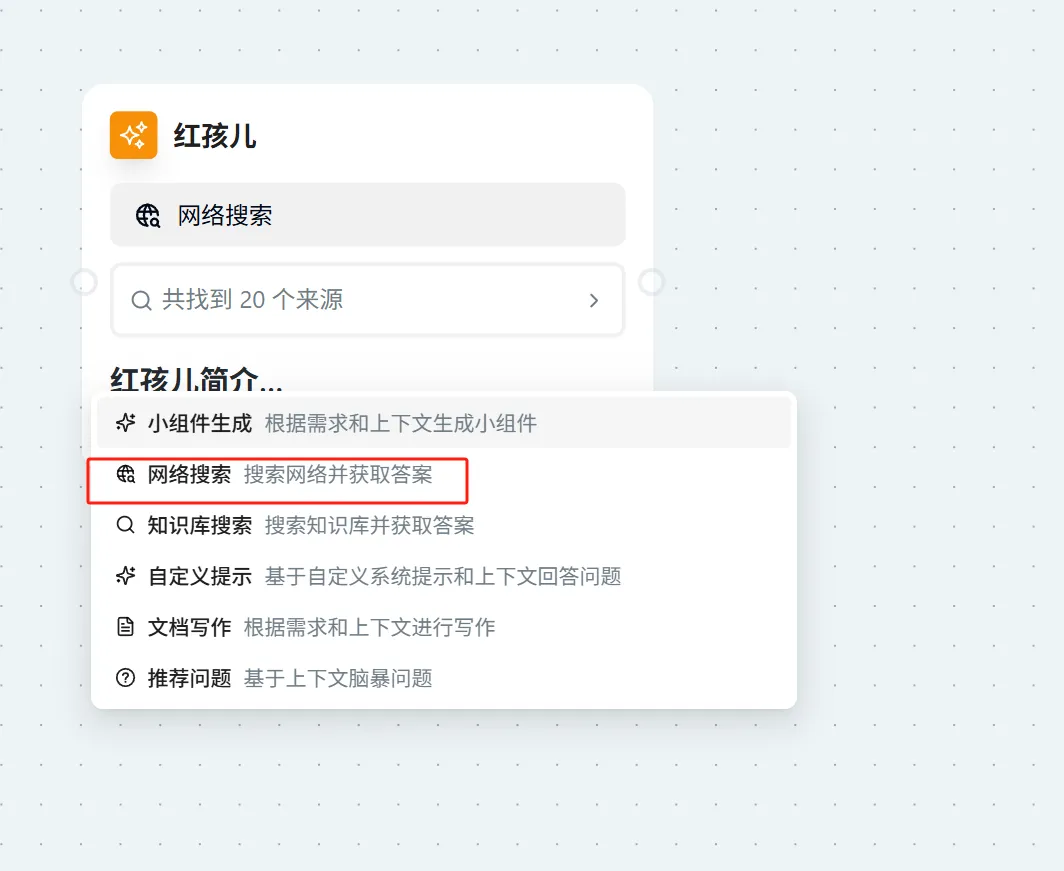
知识库搜索
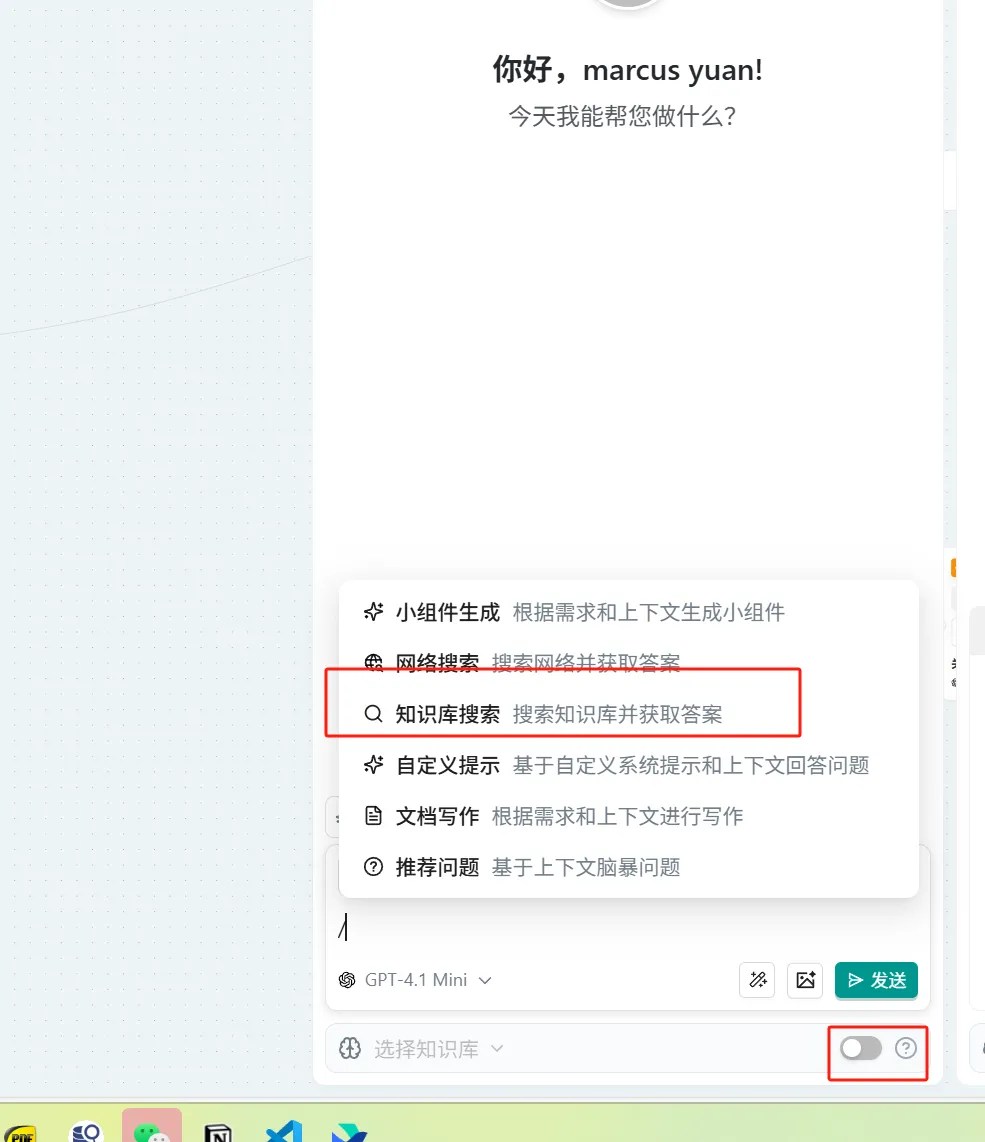
概念:对你选择添加的知识库内的画布,文件,利用emb实现召回,在结合大语言模型处理召回后的额内容,最终输出 markdown 结果(注意:当选择知识库搜索时候,默认会搜索全部知识库知识,当你选择下方的知识库开关选择对应的知识库,哪儿这个时候会选择对应的知识库作为检索对象)
操作:
- 点击页面右上角的 "问问AI" → 选择"知识库搜索"
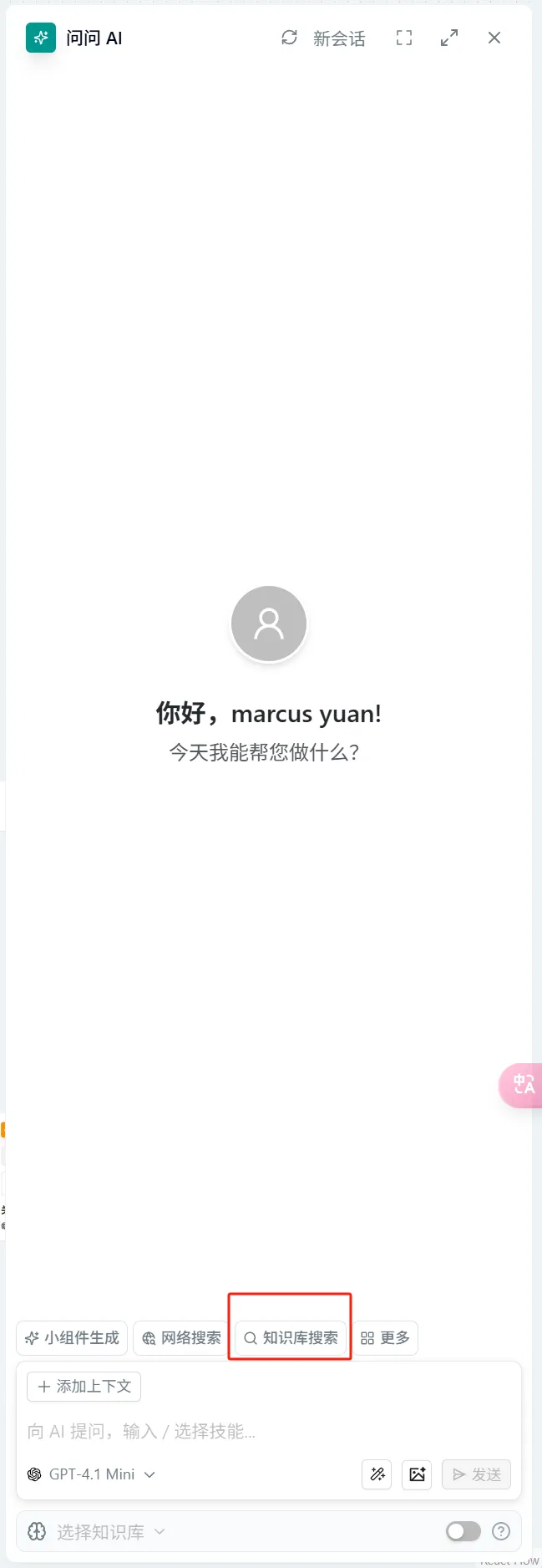
- 在"问问AI"节点中 → 在对话框输入"/"激活小组件 → 选择"知识库搜索"
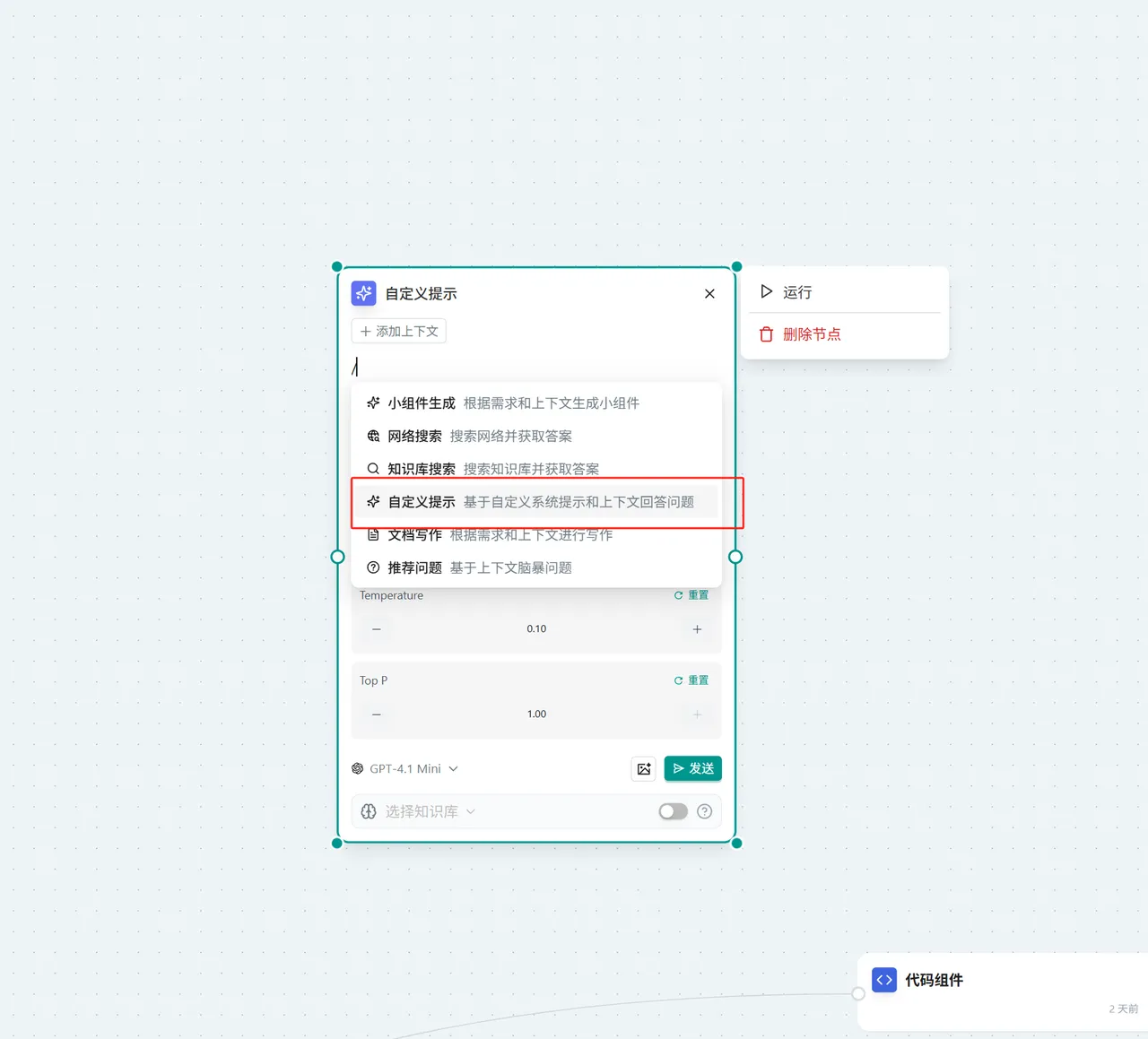
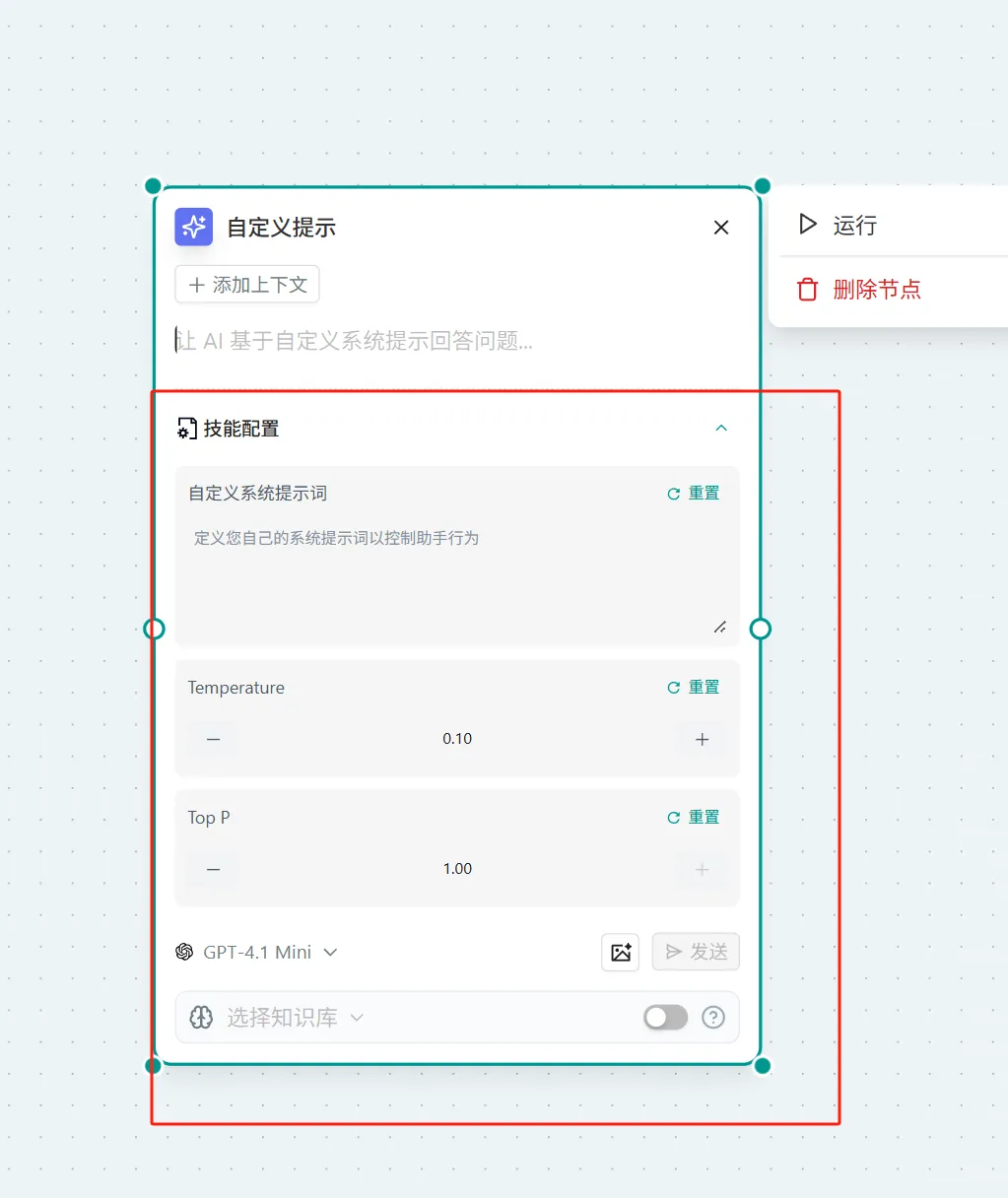
自定义提示
概念:替换掉系统的提示词,让你可以在定义系统提示词,同时可以定义Temperature 和 Top P 参数 参数详解:
| 名称 | 描述 | 适用场景 |
|---|---|---|
| 系统提示词 | 定义AI的角色、限制和行为规范,设定对话基调和上下文 | 需要明确模型角色定位的场景(如客服助手、内容创作、专业领域问答) |
| Temperature | 控制生成随机性的参数(0-2),值越高输出越多样,值越低输出越保守 | 高值适用创意写作,低值适用事实问答;默认0.7适用于大多数通用场景 |
| Top P | 核采样参数(0-1),仅从累积概率达阈值的候选词中选取,控制输出多样性 | 需要平衡创造性与相关性的场景;与temperature配合使用效果更佳(建议只调整其中一个参数) |
操作:
- 点击页面右上角的 "问问AI" → 选择"更多" → 选择"自定义提示"

- 在"问问AI"节点中 → 在对话框输入"/"激活小组件 → 选择"自定义提示"
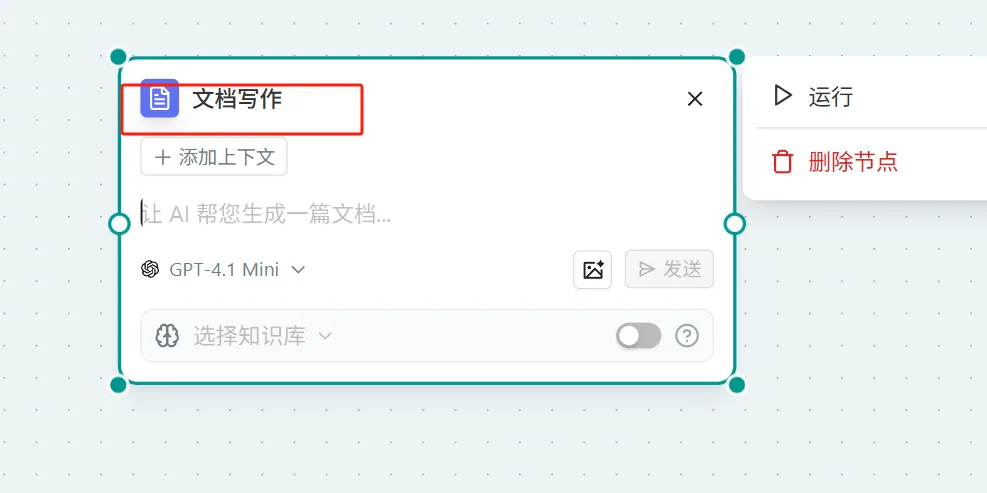
文档写作
概念:使用llm模型生生成内容,输出 markdown 思考过程,在输出一个文档节点
操作:
- 点击页面右上角的 "问问AI" → 选择"更多" → 选择"文档写作"
- 在"问问AI"节点中 → 在对话框输入"/"激活小组件 → 选择"文档写作"

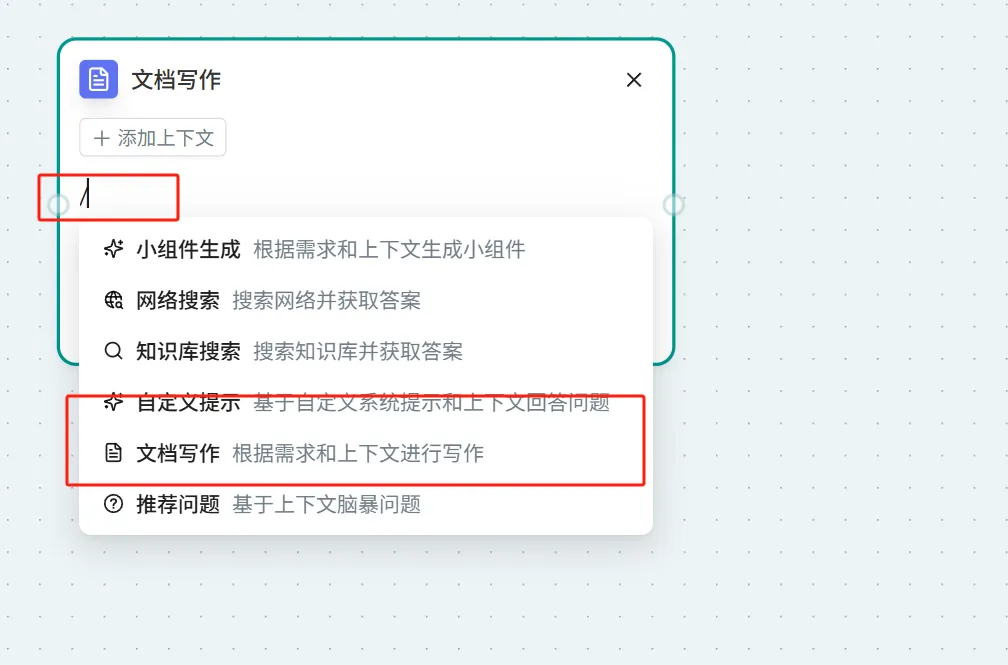
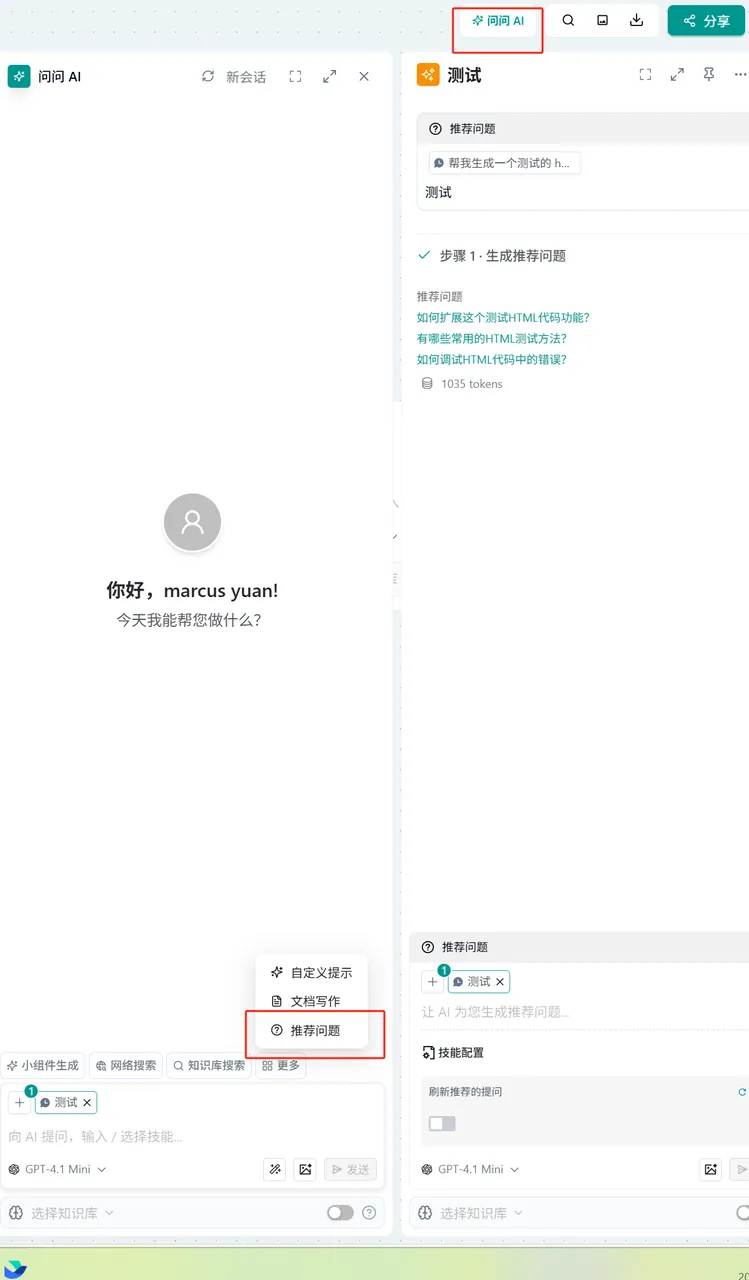
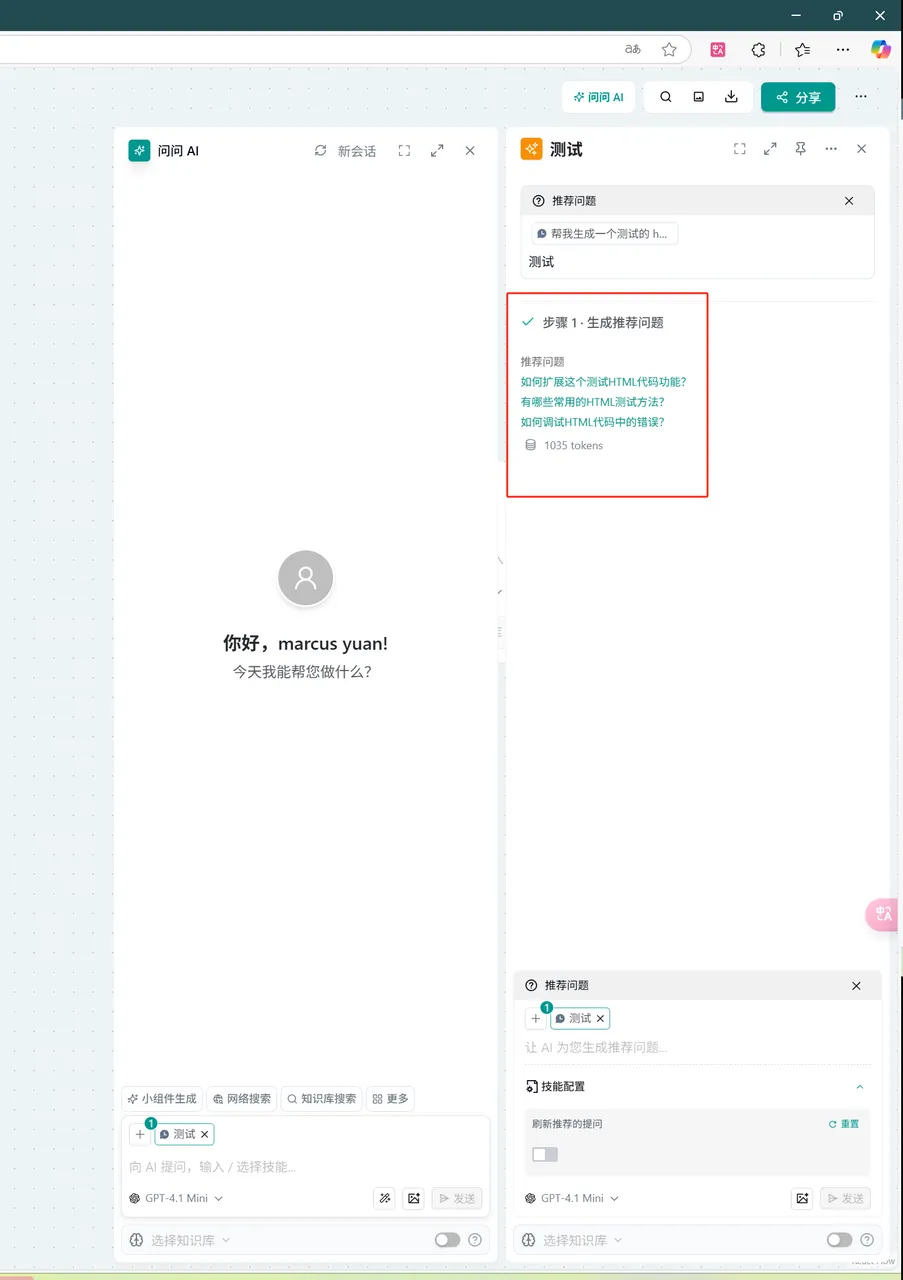
推荐问题
概念:当用戶没有创意时候根据上下文自动推断为用戶生成问题.
操作:
- 点击页面右上角的 "问问AI" → 选择"更多" → 选择"推荐问题" → 在输入框中填写问题
- 在"问问AI"节点中 → 在对话框输入"/"激活小组件 → 选择"推荐问题" → 在输入框中填写问题