Ask AI
Concept
The Ask node, as the most core node in the canvas, allows Ask AI to connect other resources through large models and fulfill user requirements using prompts:
- Add Context: By adding context, the content generated by the previous node is used as the resource to be processed by the Ask AI node.
- Select Knowledge Base: You can also add a knowledge base in Ask, enabling the large model to retrieve content from the knowledge base and generate new content in combination with prompts.
- Select Model: Choose different models based on business needs, including:
- Multimodal models (can process images)
- Think models (support chain-of-thought reasoning)
- General large models
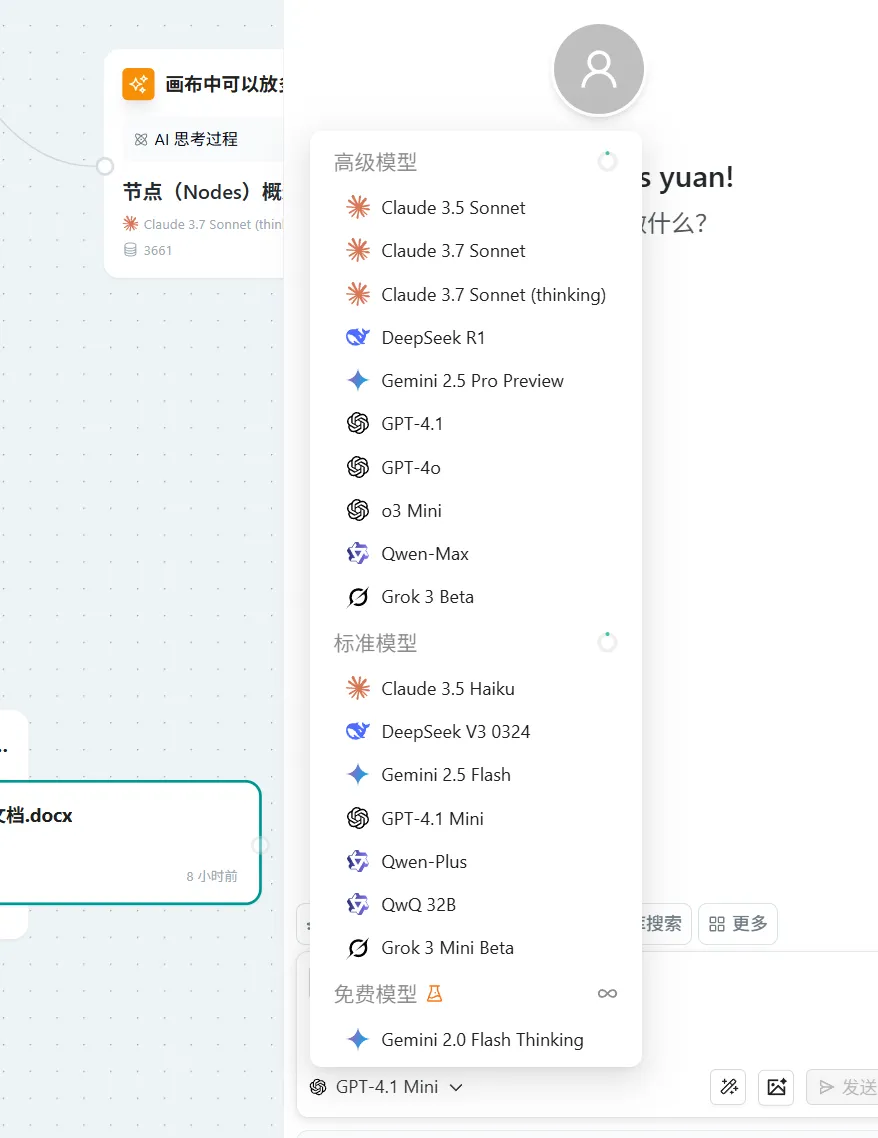
Model Selection
Choose the appropriate model based on business needs. If you need to add images, please make sure to select the corresponding visual support model.
Model Introduction
| Model Category | Model Characteristics | Model Name | Model Description (Based on public information) | Model Strengths (Based on public information) |
|---|---|---|---|---|
| Advanced Model | Multimodal | Claude 3.5 Sonnet | A model released by Anthropic, an upgrade to Claude 3 Sonnet, performing better than GPT-4o and Gemini 1.5 Pro in multiple benchmarks. Excels in coding, writing, and visual data extraction (including extracting text from imperfect images), and introduces the innovative Artifacts feature. It is the first frontier model publicly testing computer usage capabilities. | Coding, writing, visual data extraction (especially good at handling imperfect images), agent tasks, tool use, computer use (beta). Stands out in software engineering and image information extraction. |
| Advanced Model | Multimodal, Hybrid Reasoning | Claude 3.7 Sonnet | Anthropic's most intelligent model at the time of release, the first hybrid reasoning model on the market. Introduces "Extended Thinking" capability, allowing it to solve complex problems with visible, detailed steps, and respond quickly. Excels in coding and driving AI agents. | Complex problem solving (via extended thinking), advanced coding, driving AI agents, fast response generation, long text output (up to 128K tokens, some beta), supports 200K context window. |
| Advanced Model | Multimodal, Hybrid Reasoning (Optional Extended Thinking Mode) | Claude 3.7 Sonnet (Extended Thinking Mode) | An optional working mode for Claude 3.7 Sonnet. When enabled, the model spends more time on problem decomposition, plan formulation, and exploring multiple perspectives, solving complex problems through a visible, step-by-step reasoning process, performing better especially in math and science. Does not require explicit chain-of-thought prompts. | Complex problem solving, tasks requiring detailed reasoning processes (especially math, science), scenarios requiring explanation of thinking steps, deep analysis and planning. |
| Advanced Model | Think Model (Reasoning Hub) | DeepSeek R1 | A reasoning-centric model released by DeepSeek (early version was R1-Lite-Preview), using a reinforcement learning-first training approach. Aims to compete with models like OpenAI o1, excelling in logical reasoning, math, and coding, with fact-checking and complex problem planning capabilities. | Logical reasoning, code generation and completion, math problem solving (excels in AIME, MATH-500 and other benchmarks), complex problem planning and solving, fact-checking. |
| Advanced Model | Multimodal, Strong Reasoning (Can think before responding) | Gemini 2.5 Pro Preview | Google's most intelligent and powerful reasoning model preview at the time of release. Can think and reason before responding, improving performance and accuracy. Ranks high on the LMArena human preference leaderboard, with strong coding, math, and science capabilities, and supports multimodal processing and ultra-long context. | Complex reasoning (including thinking before responding), advanced code generation and understanding, math and science problem solving, multimodal information processing, long context tasks, deep research. |
| Advanced Model | Multimodal, Coding Optimized, Ultra-long Context | GPT-4.1 | A model series released by OpenAI focusing on improved coding capabilities (including standard, mini, nano). Compared to GPT-4o, it has significant improvements in coding, instruction following, and long context handling, supporting a context window of up to 1 million tokens. More robust in format adherence, reducing hallucinations, and memory, primarily available via API. | Advanced code generation and understanding, strict instruction following, ultra-long text processing (1M token context), enterprise applications, tasks requiring high format adherence and low hallucination rate. |
| Advanced Model | Multimodal (Text, Speech/Audio, Image, Video capabilities), Fast Response | GPT-4o ("omni") | OpenAI's flagship model ("o" stands for "omni"), natively integrating text, speech/audio, and visual processing capabilities. Provides GPT-4 level intelligence but is faster, with significant improvements especially in real-time voice interaction and image understanding. | Real-time multimodal interaction (voice conversation, image discussion), text generation and understanding, code generation, math and logical reasoning, fast response tasks. |
| Advanced Model | Multimodal, Enhanced Reasoning, Image Understanding | o3 Mini (OpenAI) | A new reasoning model released by OpenAI that can "think with images," i.e., analyze images and use them for reasoning. Specifically designed to handle problems requiring step-by-step logical reasoning, excelling in science, math, and coding tasks. | Image understanding and reasoning, complex problem solving, science/math/coding tasks, step-by-step logical reasoning. |
| Advanced Model | Large-scale MoE Model, Multimodal (Qwen-VL), 20T tokens training | Qwen2.5-Max (通义千问2.5-Max) | The latest version of Alibaba Cloud's Tongyi Qianwen large language model series. Surpasses DeepSeek V3 and Llama-3.1-405B in multiple benchmarks. Trained on 20 trillion tokens, it has a vast knowledge base and strong general AI capabilities. Qwen-VL is the multimodal version of this series, supporting image, text, and bounding box input and output. | Chinese natural language processing, long text summarization and generation, document Q&A, code generation, image understanding, math (improved by 75%), coding ability (improved by 102%), instruction following (improved by 105%). |
| Advanced Model | Real-time Information Retrieval, 1M token context, Reinforcement Learning, Image Analysis | Grok 3 Beta | xAI's flagship model, capable of analyzing images and answering questions. Outperforms GPT-4o in multiple AI benchmarks, has a 1 million token context window, and improved advanced reasoning capabilities through large-scale reinforcement learning. Features like DeepSearch (real-time internet analysis) and Big Brain Mode (complex tasks). | Real-time information retrieval, complex problem reasoning, math problem solving (AIME), knowledge-intensive problems (GPQA), image analysis, personalized conversations. |
| Standard Model | Fastest speed, Low latency, Efficient, 200K context | Claude 3.5 Haiku | Anthropic's fastest model, providing advanced coding, tool use, and reasoning capabilities with very low latency. Suitable for user-facing products, specialized sub-agent tasks, and generating personalized experiences from large datasets. | Fast response customer service, content moderation, simple Q&A, real-time translation, lightweight visual tasks, coding recommendations, data extraction and annotation, content moderation, processing large datasets, analyzing financial documents, generating output from long context information. |
| Standard Model | 671B MoE, 128K context, Enhanced Reasoning, Code Optimization | DeepSeek v3 0324 | An updated version of DeepSeek V3, significantly improving reasoning performance, coding ability, and tool use capabilities. Supports function calling, JSON output, and FIM completion. | Code generation and completion, math problem solving, technical documentation writing, long conversations, document analysis, retrieval-based AI applications, logical reasoning. |
| Standard Model | Lightweight, Efficient, Multimodal, 1M token context, Native Tool Use | Gemini Flash 2.0 | Google's lightweight, highly efficient model, optimized for speed and cost, supporting multimodal input and native tool use. Has a 1 million token context window. | High throughput tasks, applications requiring fast responses (like chatbots, summarization), cost-sensitive applications, multimodal reasoning, large-scale information processing. |
| Standard Model | Coding Optimized, 1M token context, Low Cost, Low Latency | GPT-4.1 Mini | A member of OpenAI's GPT-4.1 model family, focusing on coding capabilities, aiming to provide near GPT-4 level capabilities at a lower cost and latency. Has a context processing capability of up to 1 million tokens. | Tasks balancing performance and cost, general text generation, data analysis assistance, scenarios requiring good understanding but also speed, long text processing (1M token context), coding tasks. |
| Standard Model | Multimodal, Performance and Cost Balanced | Qwen-Plus (通义千问-Plus) | Alibaba DAMO Academy's model, with performance between Qwen-Max and Qwen-Turbo, offering a good balance of performance and cost. | General Chinese tasks, document processing, code writing, simple image description, natural language processing, computer vision, audio understanding. |
| Standard Model | 32B Parameters, Reinforcement Learning Fine-tuned, Enhanced Reasoning | QWQ-32B (通义千问) | An experimental research model released by Alibaba's Qwen team, built upon Qwen2.5-32B, fine-tuned with reinforcement learning to enhance reasoning capabilities. | Math reasoning (AIME 24), coding ability (LiveCodeBench), complex problem solving, chain-of-thought generation. |
| Free Model | Lightweight, Enhanced Reasoning, Real-time Information Access | Grok 3 Mini Beta | A lightweight version of xAI's Grok 3, retaining some of Grok's features like real-time information access, but smaller in scale and faster in response. | Quick information summarization, informal conversations, suitable for scenarios requiring some real-time capability but with limited computing resources, math problem solving, image analysis. |
| Free Model | Multimodal | Gemini 2.0 Flash Thinking | A variant of Gemini 2.0 Flash, emphasizing reasoning capabilities, able to think and reason before responding, thereby improving performance and accuracy. | Tasks requiring fast responses and involving some reasoning steps, educational scenarios (showing thinking process), lightweight multimodal analysis, complex reasoning, long text processing. |
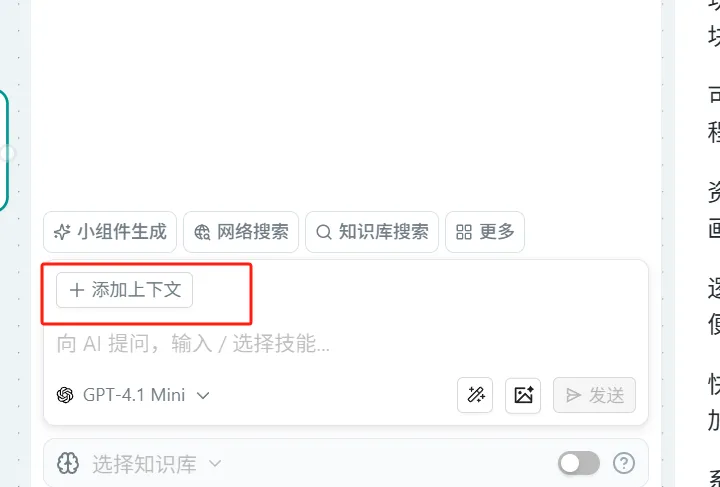
Add Context
Operation: Click "Add Context" with the mouse to add other nodes to the Ask AI node, allowing the large model to process their content.

Add Images
Operation: Method 1: Click the image add icon button on the Ask AI component to trigger the image adding action. Method 2: You can also directly cut images and use CTRL+V in the Ask dialog box or paste directly via connection to make the image a context for Ask AI. Method 3: Directly drag and drop images onto the canvas.
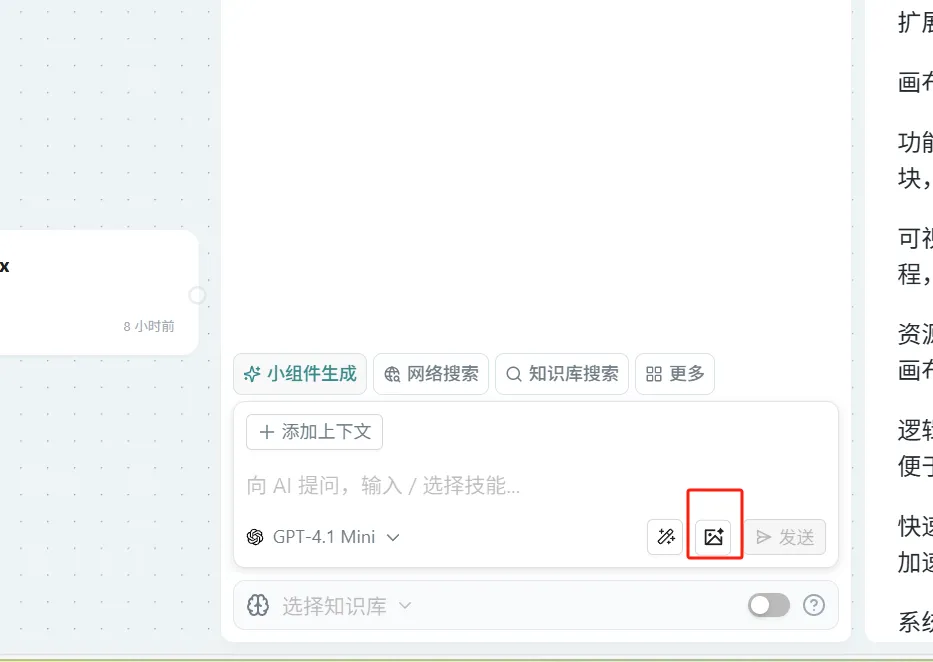
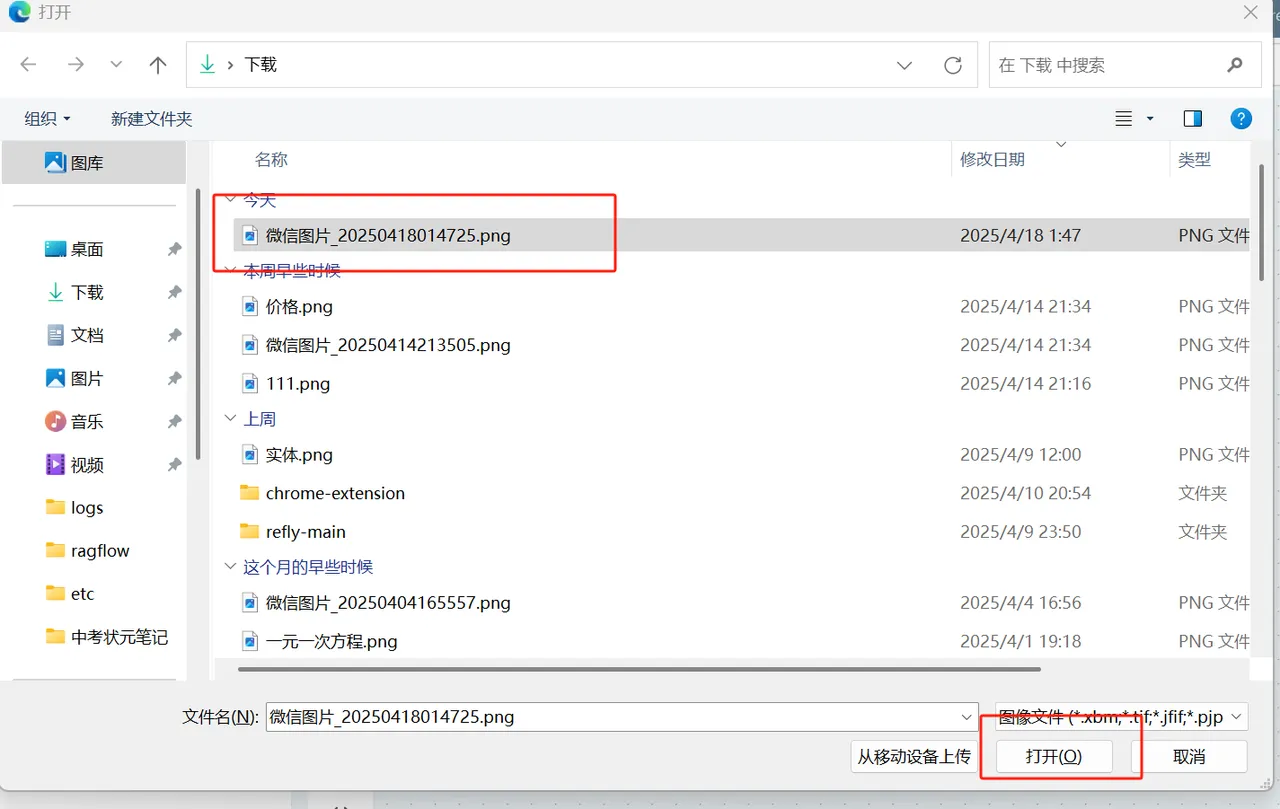
Skills
Widget Generation
Concept: Widgets are encapsulations of some system functions. When you select a widget, it calls the system's encapsulated function for that part. For example, when you call the Mind Map widget, it does two things: 1. Formats your Ask AI output into the format required by Mind Map. 2. Creates a Mind Map code block. Note: If you don't select any widget, markdown will be used for output by default. Widget Introduction:
| Name | Description | Applicable Scenarios |
|---|---|---|
| React | Used to create reusable React components, supports Hooks and UI library integration, uses Tailwind CSS for styling | When interactive UI components need to be built; displaying complex components with state management; integrating component libraries like shadcn/ui |
| SVG | Creates vector graphics, automatically rendered as visual images | When vector graphics like logos and icons need to be displayed; replacing bitmap image requests; creating scalable graphic elements |
| Mermaid | Generates flowcharts, sequence diagrams, and other visual charts | When system architecture or business processes need to be displayed; creating diagrams in technical documents; visualizing complex process relationships |
| Markdown | Supports rich text formatted document content | Creating technical documents and explanatory files; when structured display of text content is needed; creating formatted explanatory materials |
| Code | Displays code snippets in various programming languages, supports syntax highlighting | Sharing reusable code examples; when original code formatting needs to be preserved; displaying algorithm implementations or tool scripts |
| HTML | Renders complete web pages (single file including HTML/CSS/JS) | When displaying complete web page prototypes; when interactive demonstration of UI design is needed; creating self-contained web page examples (external resource references disabled) |
| Mind Map | Creates hierarchical mind maps, supports rich text nodes and interactive operations | When organizing knowledge systems; brainstorming for project planning; visualizing complex concepts; structured display of teaching materials |
Operation:
- Click "Ask AI" in the upper right corner of the page → Select "Widget Generation" → Select the corresponding widget
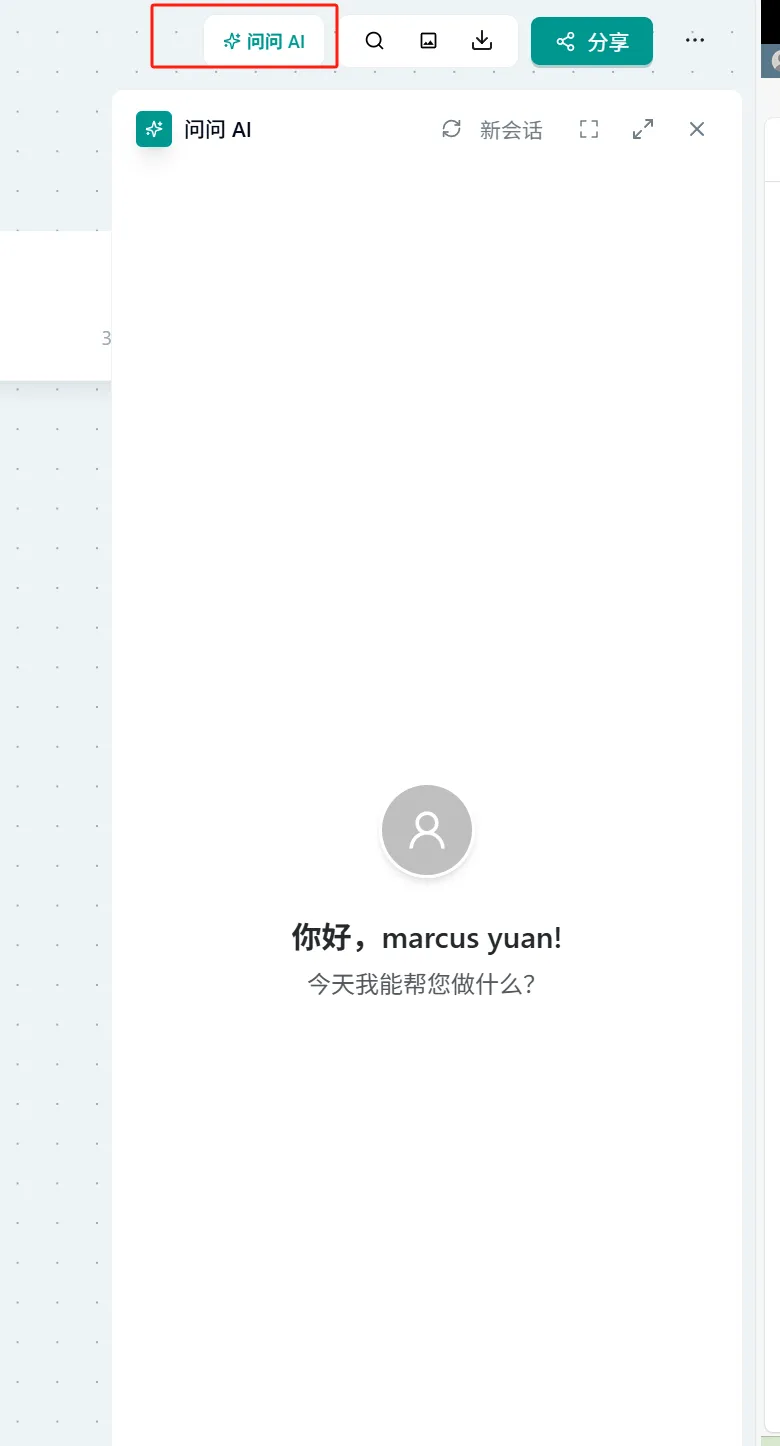
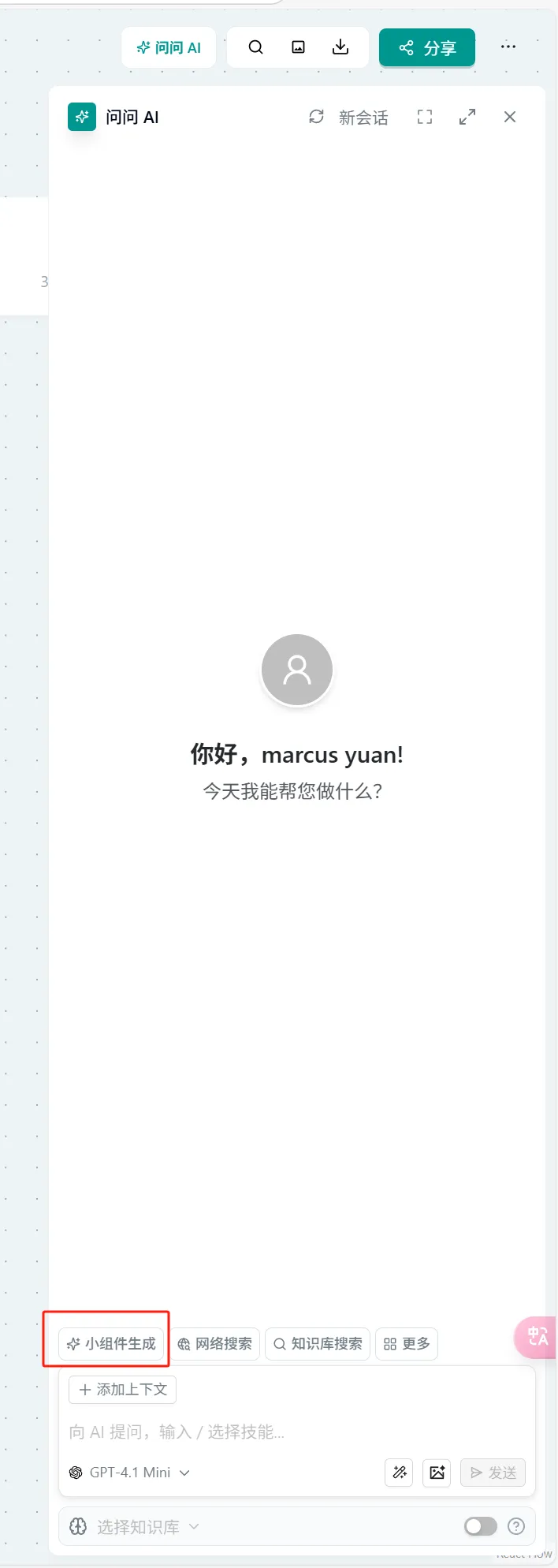

- In the input box of any Ask AI, type "/" to trigger the widget list → Select "Widget Generation" → Subsequent steps are the same as Method 1
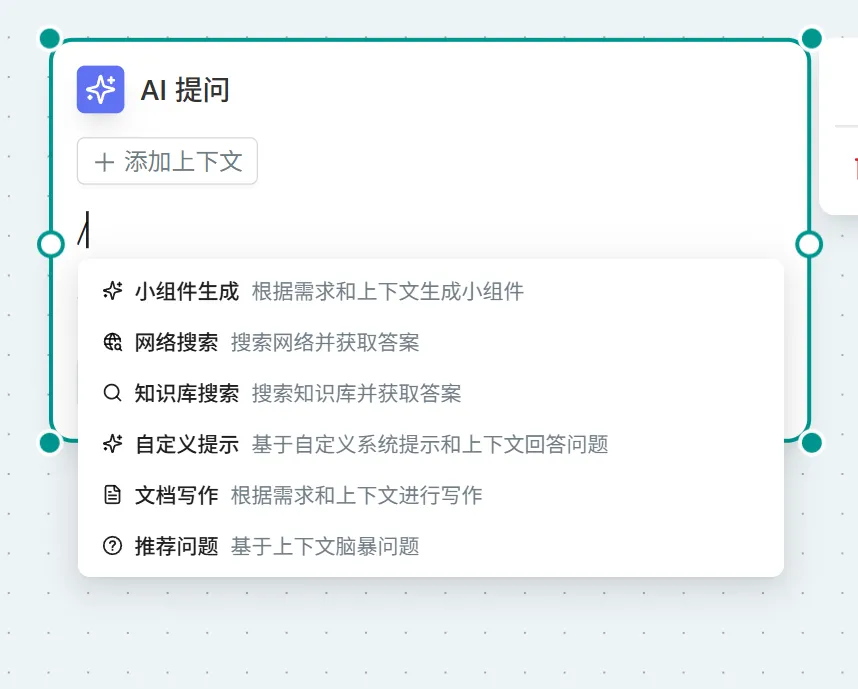
Web Search
Concept:
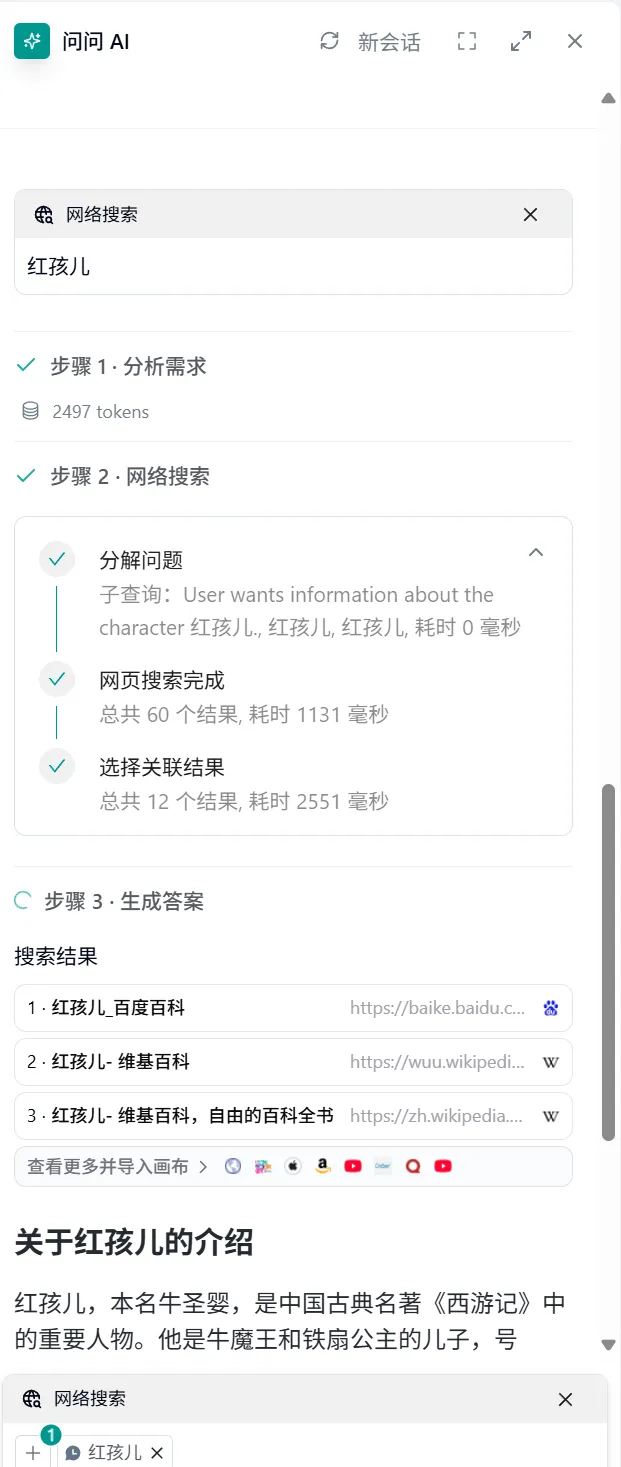
- Divided into two steps:
- Search the web for the user's question
- Process the search results using a large model and output the result
- Deep Search: Uses Deep Search technology for deep multi-round retrieval of content
Operation:
- Click "Ask AI" in the upper right corner of the page → Select "Web Search" → Directly enter search content
- Note: You can enable the Deep Search switch for deep search
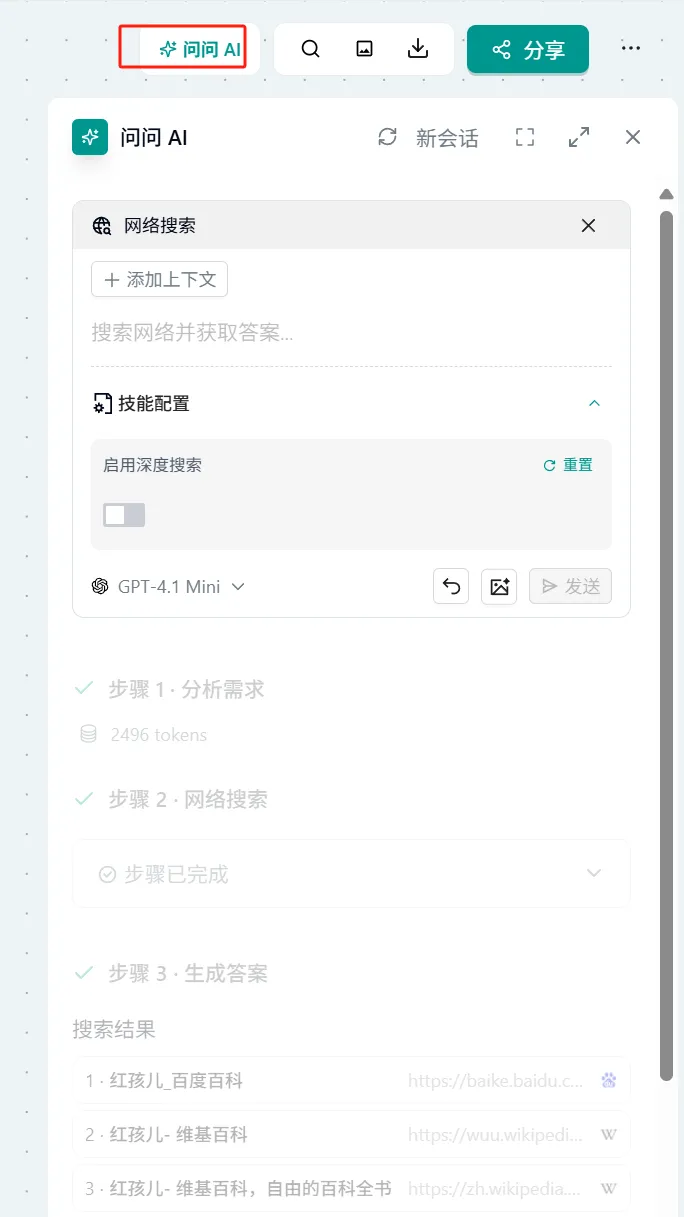
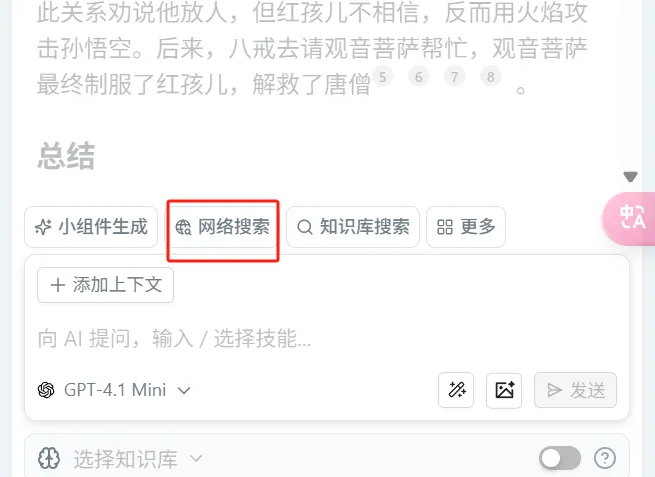



- In the input box of any Ask AI, type "/" to trigger the widget list → Select "Web Search" → Subsequent steps are the same as Method 1
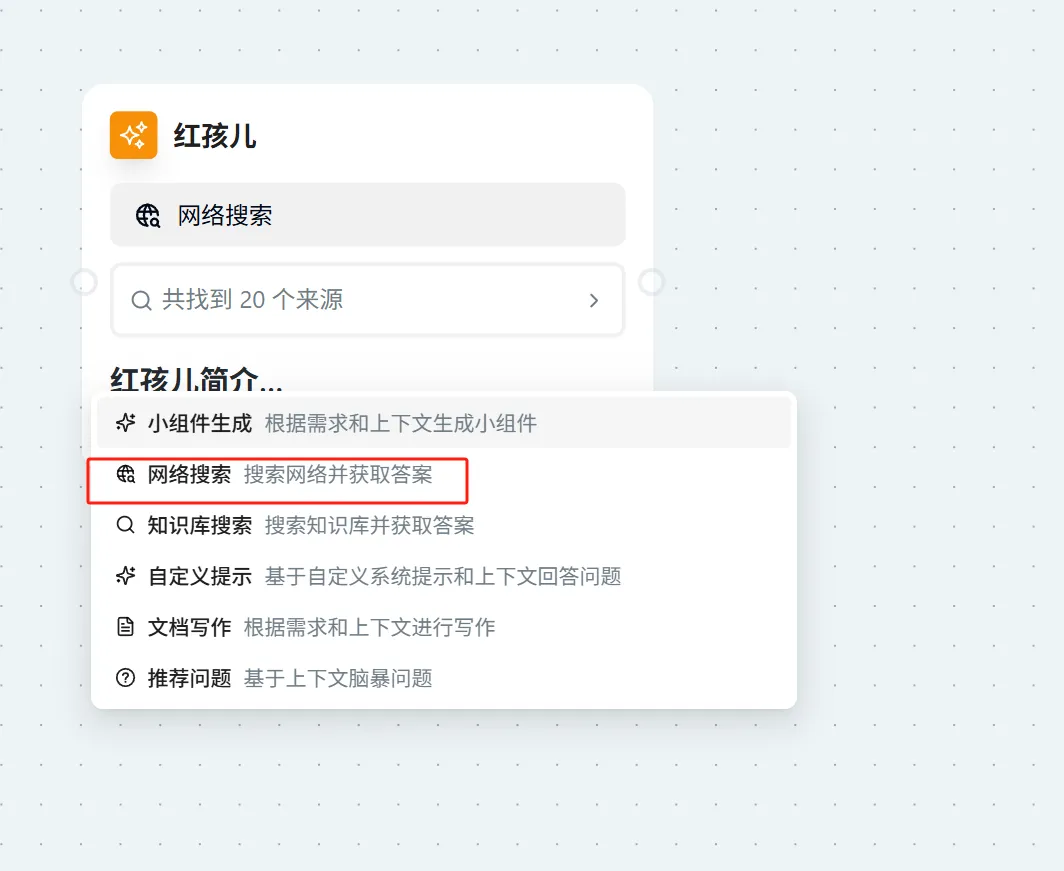
Knowledge Base Search
Concept: For the knowledge base canvases and files you have selected and added, use embedding to retrieve relevant content, combine it with a large language model to process the retrieved content, and finally output the result in markdown format (Note: When selecting Knowledge Base Search, it will search all knowledge base content by default. When you select the corresponding knowledge base using the switch below, it will use that specific knowledge base as the retrieval target).
Operation:
- Click "Ask AI" in the upper right corner of the page → Select "Knowledge Base Search"
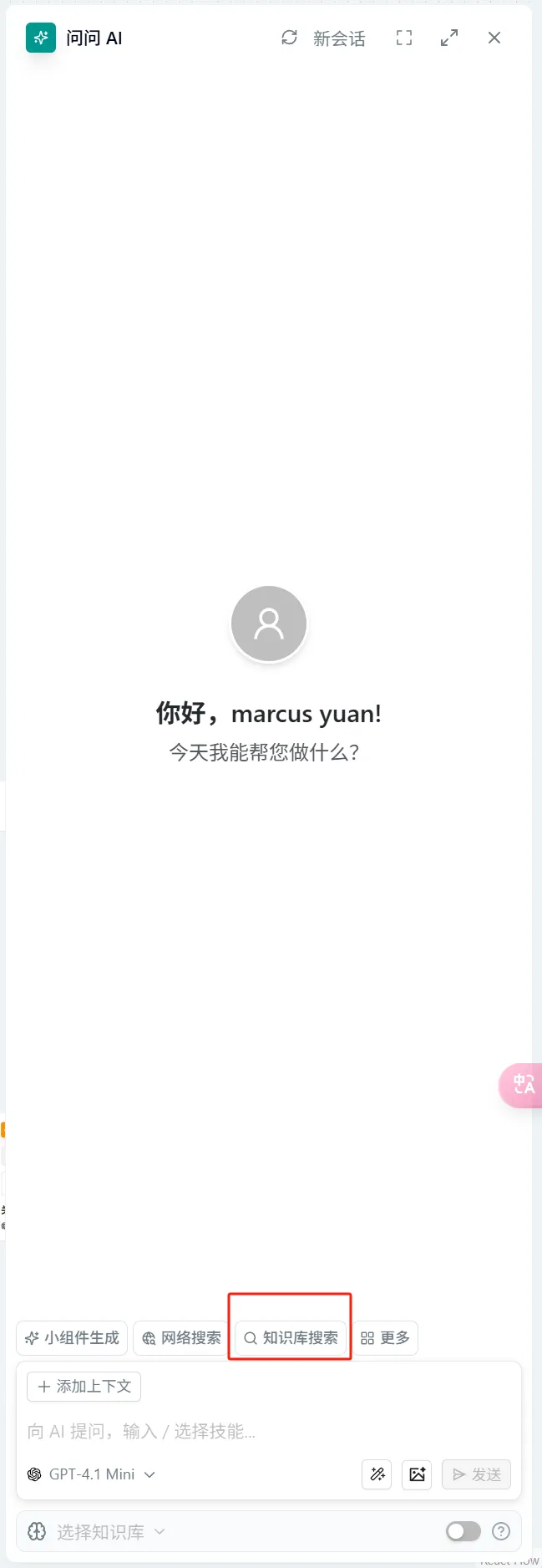
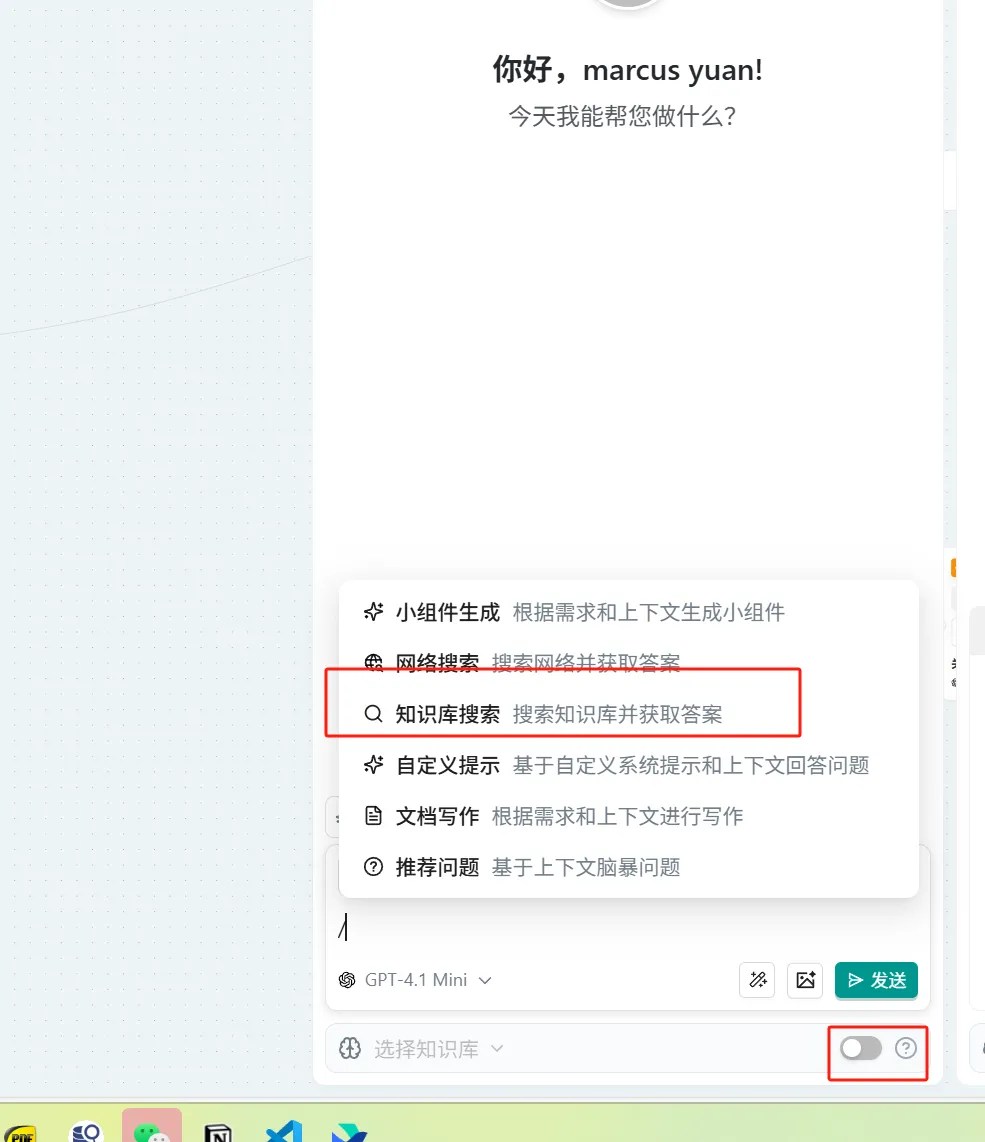
- In the "Ask AI" node → In the dialog box, type "/" to activate the widget → Select "Knowledge Base Search"
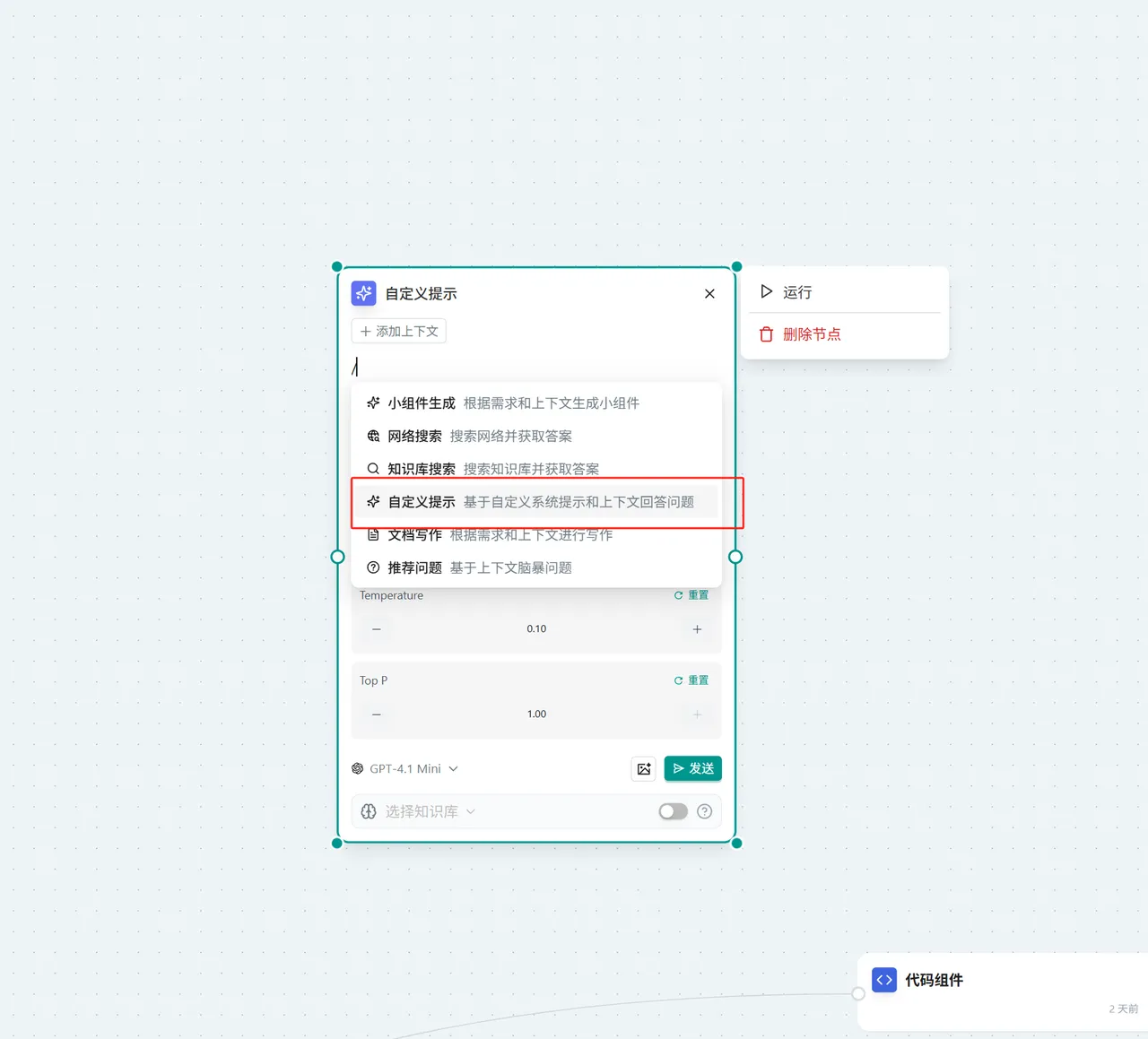
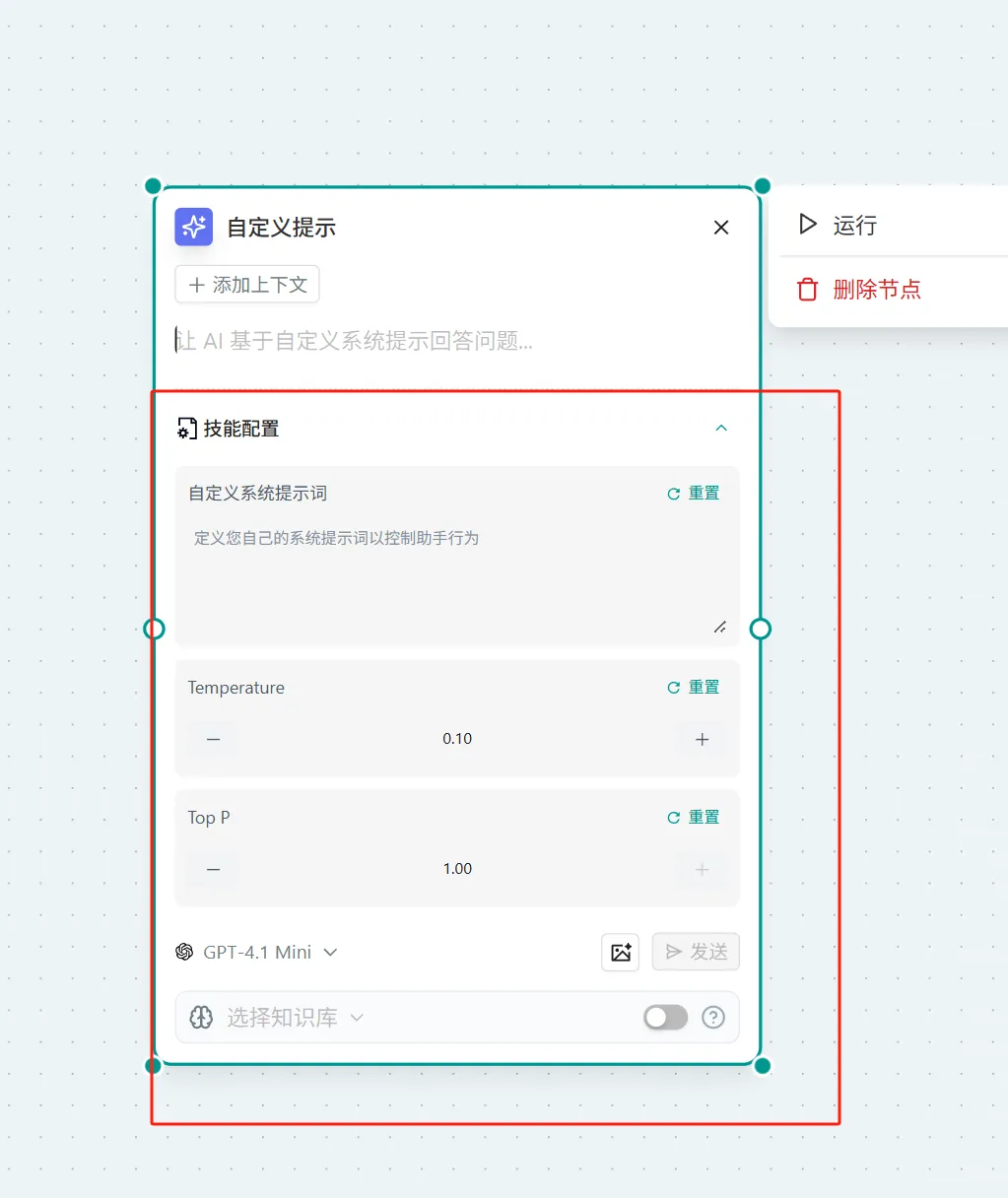
Custom Prompt
Concept: Replace the system's prompt, allowing you to define the system prompt and also define Temperature and Top P parameters. Parameter Details:
| Name | Description | Applicable Scenarios |
|---|---|---|
| System Prompt | Defines the AI's role, limitations, and behavior guidelines, setting the tone and context of the conversation | Scenarios requiring clear definition of the model's role (e.g., customer service assistant, content creation, specialized domain Q&A) |
| Temperature | Parameter controlling generation randomness (0-2), higher values result in more diverse output, lower values result in more conservative output | High values are suitable for creative writing, low values for factual Q&A; default 0.7 is suitable for most general scenarios |
| Top P | Nucleus sampling parameter (0-1), selects only from candidate words whose cumulative probability reaches the threshold, controlling output diversity | Scenarios requiring a balance between creativity and relevance; works better in conjunction with temperature (suggest adjusting only one parameter) |
Operation:
- Click "Ask AI" in the upper right corner of the page → Select "More" → Select "Custom Prompt"

- In the "Ask AI" node → In the dialog box, type "/" to activate the widget → Select "Custom Prompt"
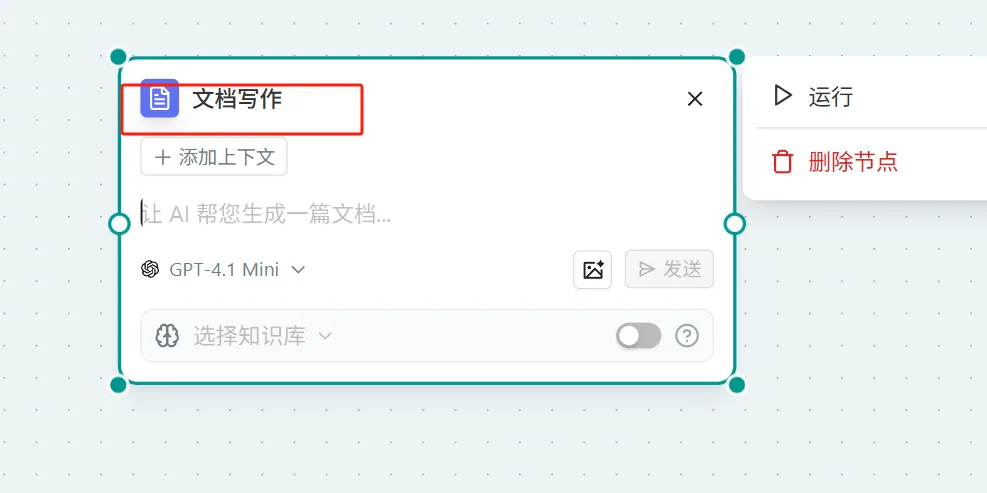
Document Writing
Concept: Use the LLM model to generate content, output the markdown thinking process, and then output a document node.
Operation:
- Click "Ask AI" in the upper right corner of the page → Select "More" → Select "Document Writing"
- In the "Ask AI" node → In the dialog box, type "/" to activate the widget → Select "Document Writing"

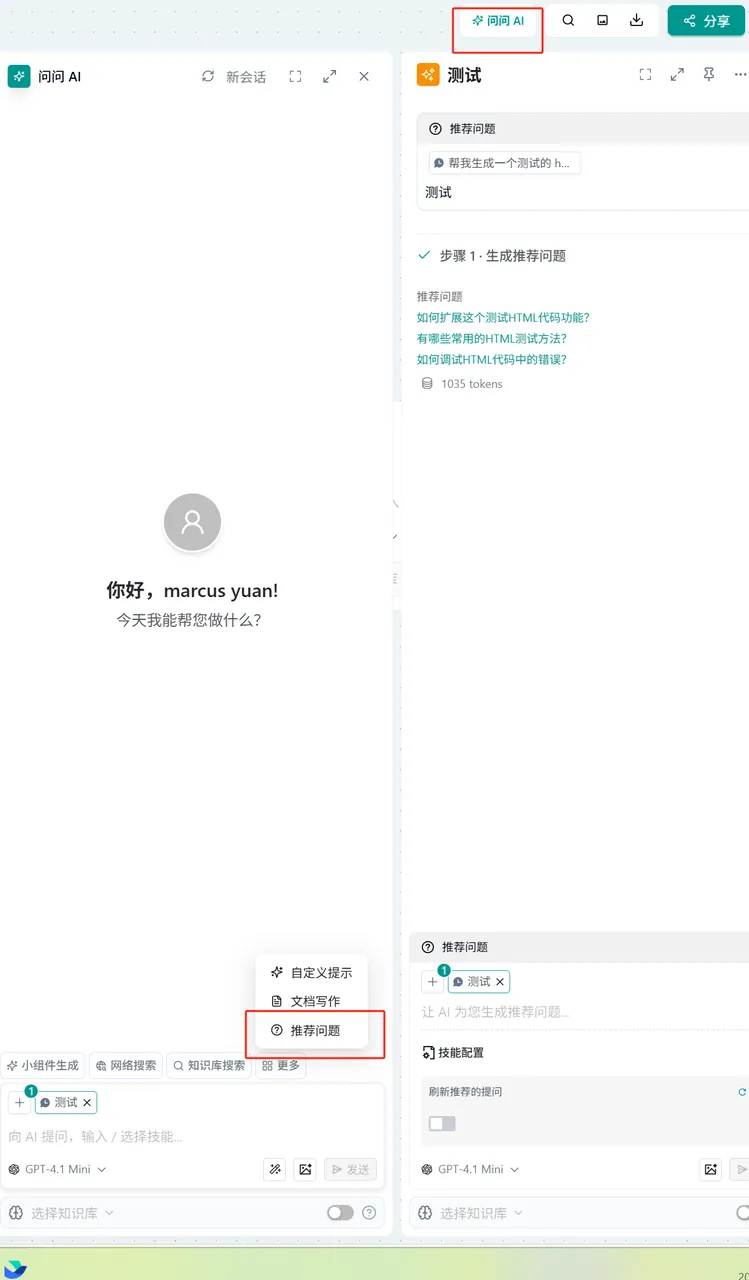
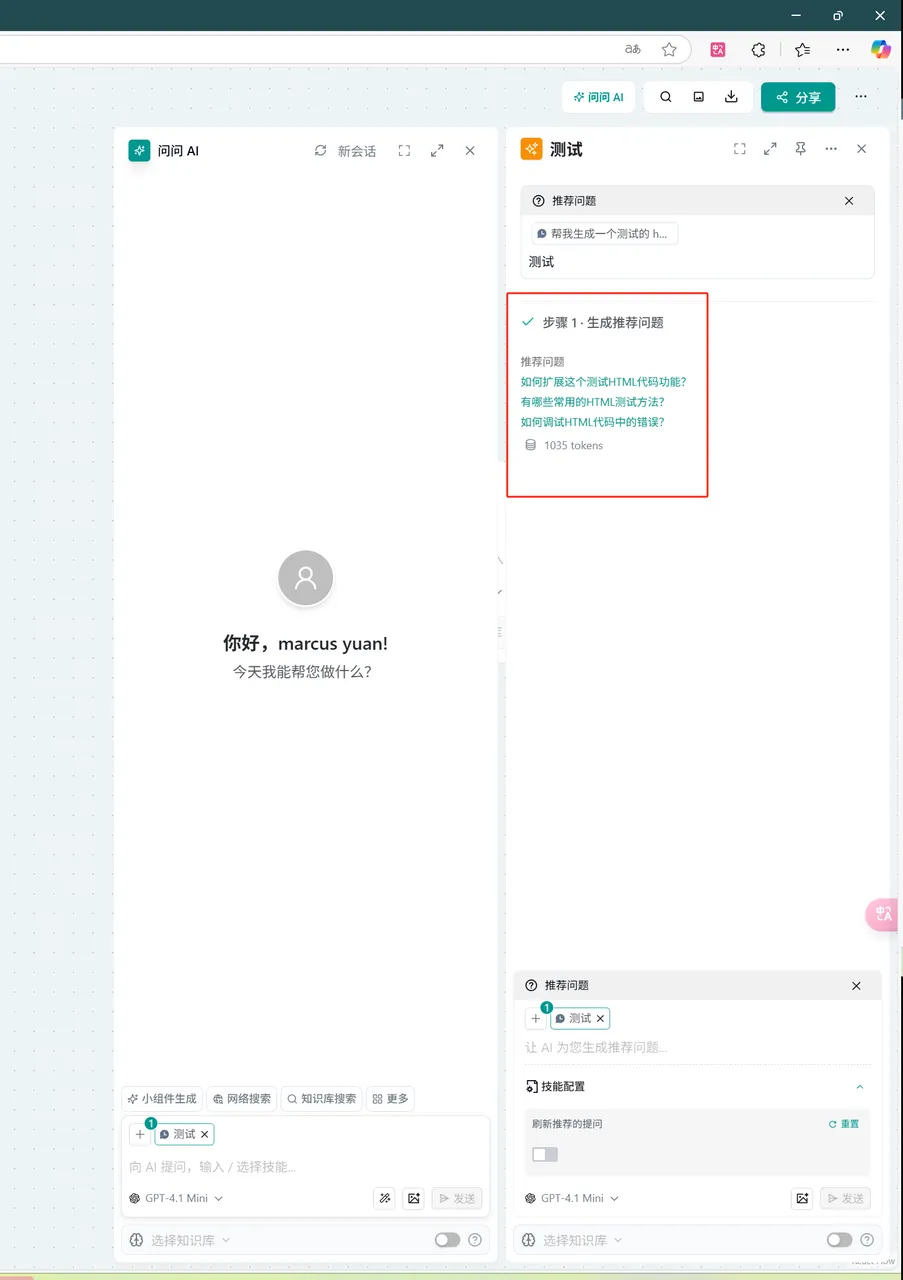
Recommended Questions
Concept: When the user lacks creativity, automatically infer and generate questions for the user based on the context.
Operation:
- Click "Ask AI" in the upper right corner of the page → Select "More" → Select "Recommended Questions" → Enter the question in the input box
- In the "Ask AI" node → In the dialog box, type "/" to activate the widget → Select "Recommended Questions" → Enter the question in the input box